[Results]
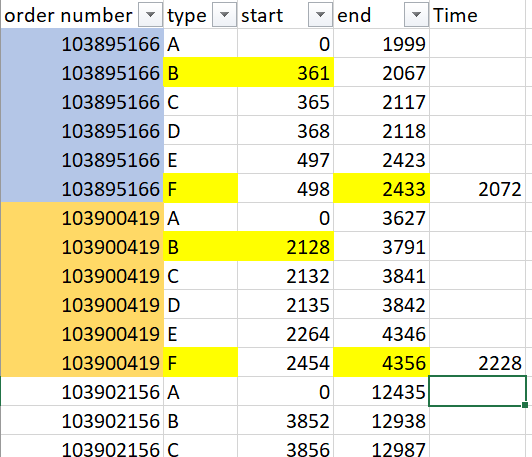
[Input data]
I have a dataframe in Python: I want to calculate the subtract of "Start" and "End" columns for each "Product order" in the following way: for each product number I have "Type"s A to D: I need to subtract the end time of D from start time of A for each product order. Any idea how to do it? Thanks.
Input data:
process order Type Start End
111 A 10 20
111 B 22 25
111 C 28 30
111 D 33 35
222 A 37 40
222 B 42 45
222
222
333
333
333
333
like for process order 111: we have D (End: 35) - A (Strat: 10) = 25 Output should be like:
process order Time_difference
111 25
222 ?
333 ?
CodePudding user response:
Group by your order and then simply take the end value from the last row and subtract from it the start value from the second row:
df.groupby('order_number').apply(lambda x: x.iloc[-1, 'end'] - x.iloc[1, 'start'])
If you need to, you can join these results back into the original df.
CodePudding user response:
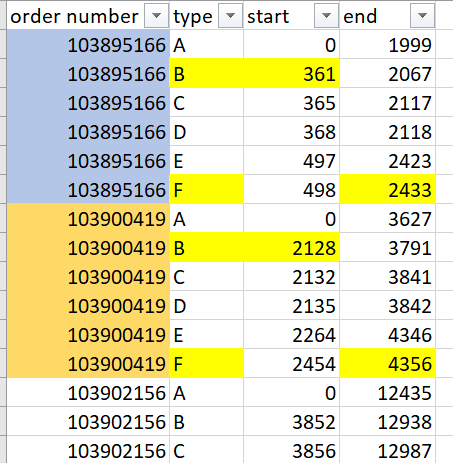
Assuming all products have Types A to F, try:
#sort values so that B is the 2nd and F is the last row for each order number
df = df.sort_values(["order number", "type"])
#groupby order number and keep the 2nd (iat[1]) row for "start" and the last row for "end"
output = df.groupby("order number").agg({"start": lambda x: x.iat[1], "end": "last"})
#compute the difference
diff = output["end"] - output["start"]
>>> diff
order number
103895166 2072
103900419 2228
103902156 9348
dtype: int64
Input df:
order number type start end
0 103895166 A 0 1999
1 103895166 B 361 2067
2 103895166 C 365 2117
3 103895166 D 368 2118
4 103895166 E 497 2423
5 103895166 F 498 2433
6 103900419 A 0 3627
7 103900419 B 2128 3791
8 103900419 C 2132 3841
9 103900419 D 2135 3842
10 103900419 E 2264 4346
11 103900419 F 2454 4356
12 103902156 A 0 12432
13 103902156 B 3852 12938
14 103902156 C 3856 12987
15 103902156 D 3860 13000
16 103902156 E 3864 13100
17 103902156 F 3868 13200