And make it looks nice too.
Here's my current data frame:
Attribute 1 Attribute 2 Attribute 3 Value
A B D 10
E 11
C F 12
H B D 10
E 11
C F 12
G 15
Something like this.
I have the sum data frame using this code:
df_sum = df.groupby('Attribute 1').sum()
as follow:
Attribute 1 Value
A 33
H 48
Here's my desired output combining the two:
Attribute 1 Attribute 2 Attribute 3 Value
A B D 10
E 11
C F 12
Subtotal for A 33
H B D 10
E 11
C F 12
G 15
Subtotal for H 48
Is something like this possible using only pandas? Thanks.
CodePudding user response:
To maintain the original sorting I would solve it using a loop groupby
import pandas as pd
df = pd.DataFrame({
'Attribute1': ['A', 'A', 'A', 'H', 'H', 'H', 'H'],
'Attribute2': ['B', 'B', 'C', 'B', 'B', 'C', 'C'],
'Attribute3': ['D', 'E', 'F', 'D', 'E', 'F', 'G'],
'Value': [10, 11, 12, 10, 11, 12, 15]
})
df = df.groupby(['Attribute1', 'Attribute2', 'Attribute3']).sum()
df_out = [] # init output list
for index, df_sub in df.groupby(level=0): # loop groupby level 0
df_sub = df.groupby('Attribute1').sum().reset_index() # get subtotal and reset index
df_sub['Attribute1'] = df_sub['Attribute1'].replace({index: f"{index}_subtotal"}) # rename index value to include subtotal
df_sub['Attribute2'] = '' # dummy value for Attribute 2
df_sub['Attribute3'] = '' # dummy value for Attribute 3
df_sub = df_sub.groupby(['Attribute1', 'Attribute2', 'Attribute3']).sum() # match groupby structure so we can use append
df_out.append(df.loc[index:index].append(df_sub)) # select current index value and append subtotal
df_out = pd.concat(df_out) # merge list to DataFrame
This gives you the desired output
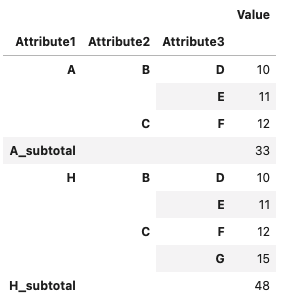
CodePudding user response:
Here is one way, you have to be strategic with values due to alphabetical sorting:
df_sum=df.groupby('Attribute 1').sum()
df_sum['Attribute 2'] = 'Sub'
df_sum['Attribute 3'] = 'Total'
df_sum = df_sum.set_index(['Attribute 2', 'Attribute 3'], append=True)
pd.concat([df, df_sum]).sort_index()
Output:
Value
Attribute 1 Attribute 2 Attribute 3
A B D 10
E 11
C F 12
Sub Total 33
H B D 10
E 11
C F 12
G 15
Sub Total 48