I have a file which looks like below, however you should note that in reality the file contains more then 100.000 records.
blue black red 250
red black blue 140
black yellow purple 100
orange blue blue 140
blue black red 250
red black blue 140
black yellow purple 700
orange blue blue 200
I also have a list which contains the following values my_list = ['140', '700', '800']
Now I want the following:
- If one of the values of
my_listoccurs in the filerow[3]I want to append the whole record to a new list. - If one of the values of my list does not occur in the file row[3] I want to append the value itself and the rest of the values should be
'unknown'.
This is my code:
new_list = []
with open(my_file, 'r') as input:
reader = csv.reader(input, delimiter = '\t')
row3_list = []
for row in reader:
row3_list.append(row[3])
for my_number in my_list :
if my_number in row3_list :
new_list.append(row)
elif my_number not in row3_list :
new_list.append(['Unknown', 'Unkown', 'Unkown', row[3]])
This is my desired output:
red black blue 140
orange blue blue 140
red black blue 140
black yellow purple 700
unknown unkown unkown 800
My problem: Like I mentioned my file contains a bulk of records could be more then 100.000 . So above way is taking ages. I have been waiting for output for about 15 minutes now but still nothing.
CodePudding user response:
you can use numpy and pandas to get more efficient:
import pandas as pd
import numpy as np
# read file to dataframe
df = pd.read_csv('file.txt', delim_whitespace=True, header=None)
# give names to columns for simplicity
df.columns = ['a','b', 'c', 'd']
# our values
my_list = ['140', '700', '800']
my_second_list = ['orange', 'red']
# filter rows that not in my_list
new_df = df[df['d'].isin(my_list) & df['a'].isin(my_second_list)]
# find values in my_list that are not in file
missing = np.setdiff1d(np.asarray(my_list), new_df['d'].unique().astype(str))
# add there rows with unknown
for i in missing:
d = {'a': ['unknown'], 'b': ['unknown'], 'c': ['unknown'], 'd': i}
temp = pd.DataFrame(data=d)
new_df = new_df.append(temp, ignore_index=True)
result = new_df.values.tolist()
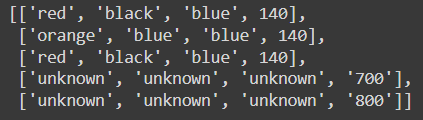
output for given data sample:
CodePudding user response:
Try this (you need to install pandas with pip install pandas):
import pandas as pd
df = pd.read_csv('myfile.txt', sep='\t', header=None, dtype=str,
names=('0', '1', '2', '3'))
result = df[df['3'].isin(my_list)]
vals = df[~df.index.isin(result.index)]['3']
if len(vals) > 0:
tot = vals.map(int).sum()
result = result.append(
{'0': 'unknown', '1': 'unknown', '2': 'unknown',
'3': vals.map(int).sum()},
ignore_index=True,
)
result = result.values.tolist()
If you don't want to use pandas then I would do something like this:
import bisect
import csv
def elem_in_list(lst, x):
i = bisect.bisect_left(lst, x)
if i != len(lst) and lst[i] == x:
return True
return False
my_list = ['140', '700', '800']
result = []
tot = 0
is_tot_used = False
lst = sorted(list(map(int, my_list)))
with open('myfile.txt') as input:
reader = csv.reader(input, delimiter='\t')
for row in reader:
if elem_in_list(lst, int(row[3])):
result.append(row)
else:
is_tot_used = True
tot = int(row[3])
if is_tot_used:
result.append(['unknown'] * 3 [tot])
If my_list is large then this code will be much faster than yours. Why? Because searching a sorted list can be done in O(log(n)), while searching an unsorted list can be done in O(n).
CodePudding user response:
Import your csv file as a Pandas Data Frame
import pandas as pd
A = [['blue', 'black', 'red', 250],
['red', 'black', 'blue', 140],
['black', 'yellow', 'purple', 100],
['orange', 'blue' , 'blue', 140],
['blue', 'black', 'red', 250],
['red', 'black' , 'blue' , 140],
['black', 'yellow', 'purple', 700],
['orange', 'blue' , 'blue' , 200]]
df = pd.DataFrame(A,columns=['A','B','C','D'])
df_ = pd.DataFrame(columns=['A','B','C','D'])
my_list = ['140', '700', '800']
for ii in my_list:
temp = df.loc[df['D'].isin([int(ii)])]
if len(temp.index):
df_ = df_.append(temp)
else:
to_append = ['unknown', 'unknown', 'unknown', int(ii)]
df_.loc[len(df_)] = to_append
print(df_)
CodePudding user response:
I think it's possible to simplify the code you have to avoid the second for loop. If you try something like this, it ought to finish in a more reasonable amount of time:
new_list = []
my_file = "some_file.txt"
my_list = ['140', '700', '800']
with open(my_file, 'r') as input:
reader = csv.reader(input, delimiter = '\t')
for row in reader:
if row[3] in my_list:
new_list.append(row)
else:
new_list.append(['Unknown', 'Unkown', 'Unkown', row[3]])