Six of them are: UTF7 BigEndianUnicode, Unicode, the Default, ASCII, UTF8, UTF32
There is one of the most important son: ANSI, the son here and there were 140 sons, one of which is a "Chinese simplified (GB2312)"
-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- cut -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
Combining with the System. Text Encoding, said the discovery process
By the attribute
public static Encoding UTF7 {get; }
Public static Encoding BigEndianUnicode {get; }
Public static Encoding Unicode {get; }
Public static Encoding Default {get; }
Public static Encoding ASCII {get; }
Public static Encoding UTF8 {get; }
Public static Encoding UTF32 {get; } Know that there are 6 kinds of encoding and the Default of getting to yes is this one of the six;
After the operation found that the "Chinese simplified (GB2312)", is not one of the six,
Baidu knows "Chinese simplified (GB2312)" is one of the ANSI including;
Thus, ANSI is a kind of coding way of Encoding (with references) after, just don't know why not listed in primitive properties,
Two, so want to know how many sons, ANSI found GetEncodings in Encoding method, running after
Lists 140 kinds,
Attachment 1:
Run the c # code
String Str="case";
Console. WriteLine (" ASCII Encoding for "+ HttpUtility. UrlEncode (Str, System. Text. Encoding. ASCII));
Console. WriteLine (" coding BigEndianUnicode as "+ HttpUtility. UrlEncode (Str, System. Text. Encoding. BigEndianUnicode));
Console. WriteLine (" is the Default Encoding for "+ HttpUtility. UrlEncode (Str, System. Text. Encoding. The Default));
Console. WriteLine (" Unicode Encoding for "+ HttpUtility. UrlEncode (Unicode) Str, System. Text. Encoding.);
Console. WriteLine (" coding UTF32 as "+ HttpUtility. UrlEncode (Str, System. Text. Encoding. UTF32));
Console. WriteLine (" coding UTF7 as "+ HttpUtility. UrlEncode (Str, System. Text. Encoding. UTF7));
Console. WriteLine (" Encoding UTF8 as "+ HttpUtility. UrlEncode (Str, System. Text. Encoding. UTF8));
Console. WriteLine (" coding UTF32 as "+ HttpUtility. UrlEncode (Str, System. Text. Encoding. UTF32));
Console. WriteLine (" -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- ");
Var DefaultCode=System. Text. Encoding. The Default;
Console. WriteLine (DefaultCode. BodyName);
Console. WriteLine (" -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- ");
Var ss=System. Text. Encoding. GetEncodings ();
Console. WriteLine ($" total {ss. GetLength (0). The ToString ()}, ");
The foreach (var item in ss)
{
. "Console. WriteLine (${item Name} {item. CodePage} \ \ t t {item. GetEncoding ()}");
}
Results:
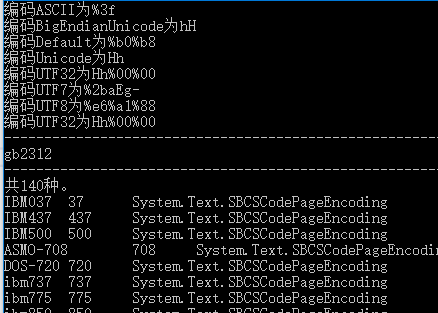
Second, reference:

From the link: https://www.iteye.com/blog/wallimn-539595
Finally, although the conclusion is the afternoon effort;
But always feel guilty, think it wrong (esp),
Please confirm the great god,
CodePudding user response:
Encourage,So-called coding, that is, a character in a way out, such as my own invention:
A: 0001
2:0002
9:0003
Ten: 0010
You: 1234
I: 1235
It: 1236
.
Also a kind of coding, but this code doesn't come, only my own use,
Some people often use, better known coding, was included in Encoding, under the static properties of seven Encoding is mentioned,
The seven inside, there are four fully support Unicode (explained later) :
Encoding. Unicode (name actually wrong, be misleading and should be written in Encoding. UTF16)
Encoding. BigEndianUnicode
. Encoding UTF8
Encoding. UTF32
The other three, ASCII and UTF7 is legacy code, can't represent all the Unicode code point,
And Encoding. The Default is actually the not a specific coding, it is the current machine MBCS code page (and) caused by left over by history,
All it may be the iso - 8859-1, may also be a gb2312, they probably will again in the future UTF8, etc.,
Old system (such as Windows3.0) only support some code, need to know the coding way, this is the origin of the current machine MBCS code page, but this method is very poor, commonality with the progress of technology, people are aware of the need to have a unified code scheme, that is the emergence of Unicode Unicode can also be called a unified code - under the Unicode, the specific point of a character code is , for example, if the third line you can't see the characters, and may your system/browser does not support) :
: U + 7684
A: U + 0041
?? : U + 1 f495
By UTF - 16 is:
: Encoding. Unicode. Get string (new byte [] x76} {x84 0, 0).
A: Encoding. Unicode. Get string (new byte [] {0 x41, 0 x00});
?? : Encoding. Unicode. Get string (new byte [] {xd8 0 x3d, 0, 0 x95, 0 XDC});
As you can see, the UTF - 16, most of the code can be used two bytes, it directly with the code point number, such as {0 x41, 0 x0} is 0 x0041, x76} {0 x84, 0 is 0 x7684, however, some code point two bytes not put, such as the U + 1 f495, UFT - 16, using a prefix that a particular need 4 bytes, interested friends can reference UTF - 16 coding,
Use UTF - 32 to say is:
: Encoding. UTF32. Get string (new byte [] {0 x84, 0 x76, 0 x00 to 0 x00});
A: Encoding. UTF32. Get string (new byte [] {0 x41, 0 x00, 0 x00 to 0 x00});
?? : Encoding. UTF32. Get string (new byte [] {0 x95, 0 xf4, 0 x01, 0 x00});
UTF - 32 fixed with 32 bit, 4 bytes to represent the code, you can transfer directly and Unicode code points, such as {0 x95, 0 xf4, 0 x01, 0 x00} is U + 1 f495
By BigEndianUnicode is:
: Encoding. BigEndianUnicode. Get string (new byte [] x84} {x76 0, 0).
A: Encoding. BigEndianUnicode. Get string (new byte [] {0 x00 to 0 x41});
?? : Encoding BigEndianUnicode (new byte [] {XDC xd8 0, 0 x3d, 0, 0 x95,});
BigEndian said "heel in the former", that is, in every 16 bits, big-endian byte in the front, interested friends to compared with UTF - 16,
Use UTF8 said:
. : Encoding UTF8. Get string (new byte [] x84} {0 xe7, x9a 0, 0).
A: Encoding UTF8. Get string (new byte [] x41 {0}).
?? : Encoding UTF8. Get string (new byte [] {x9f 0 xf0, 0, 0 x92, 0 x95});
Is variable length encoding UTF8, conventional Ascii characters if within 127, can be expressed in a byte, so x41 {0} says U + 0041,
Many characters in UTF8 encoding is two bytes, but UTF8 encoding efficiency is not high, Chinese tend to be expressed with three bytes, interested friends can see UTF8 standard,
Expressed in GB2312 is:
: Encoding. GetEncoding (" GB2312 "). Get string (new byte [] xc4} {xb5 0, 0).
nullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnull