I want to transform my XML file into a dataframe pandas I tried this code
import pandas as pd
from bs4 import BeautifulSoup
soup = BeautifulSoup(open("C:/Users/user/Desktop/essai/dataXml.xml", "r"),"xml")
d = {}
for tag in soup.RECORDING.find_all(recursive=False):
d[tag.name] = tag.get_text(strip=True)
df = pd.DataFrame([d])
print(df)
and this is a portion of my XML data
<?xml version="1.0" encoding="utf-8"?>
<sentences>
<sentence>
<text>We went again and sat at the bar this time, I had 5 pints of guinness and not one buy-back, I ordered a basket of onion rings and there were about 5 in the basket, the rest was filled with crumbs, the chili was not even edible.</text>
<aspectCategories>
<aspectCategory category="place" polarity="neutral"/>
<aspectCategory category="food" polarity="negative"/>
</aspectCategories>
</sentence>
</sentences>`
and I got this error
for tag in soup.RECORDING.find_all(recursive=False):
AttributeError: 'NoneType' object has no attribute 'find_all'
How can I fix it?
and thank you in advance
edit:
replacing soup.RECORDING.find_all with soup.find_all fixed the error but still I don't get what I want
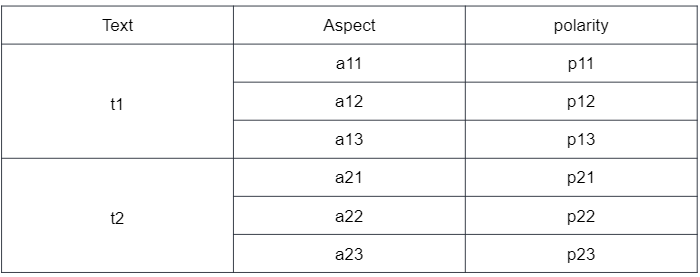
I want something like this
CodePudding user response:
Try this code:
d = {
'text': [],
'aspect': [],
'polarity': []
}
for sentence in soup.find_all('sentence'):
text = sentence.find('text').text
for ac in sentence.find_all('aspectCategory'):
d['text'].append(text)
d['aspect'].append(ac.get('category'))
d['polarity'].append(ac.get('category'))
df = pd.DataFrame(d)
Output:
>>> df
text aspect polarity
0 We went again and sat at the bar this time, I ... place place
1 We went again and sat at the bar this time, I ... food food
CodePudding user response:
Consider the new pandas 1.3.0 method, read_xml, but join two calls for the different level of nodes. Default parser is lxml but can use the built-in etree to avoid the third-party XML package.
import pandas as pd
import xml.etree.ElementTree as et
xml_file = "C:/Users/user/Desktop/essai/dataXml.xml"
doc = et.parse(xml_file)
df_list = [
(pd.read_xml(xml_file, xpath=f".//sentence[{i}]", parser="etree")
.join(pd.read_xml(
xml_file,
xpath=f".//sentence[{i}]/aspectCategories/*",
parser="etree"
))
) for i, s in enumerate(doc.iterfind(".//sentence"), start=1)
]
df = pd.concat(df_list)