I am working with the R programming language. I have the following code that creates 100 data sets (containing a fixed component and a random component):
a = rnorm(300,10,5)
b = rnorm(300,3,1)
c = rnorm(300,12,1)
e = "original"
d = data.frame(a,b,c,e)
results <- list()
for (i in 1:100){
a = rnorm(100,10,10)
b = rnorm(100,10,10)
c = rnorm(100,10,10)
e = "simulated"
d_i = data.frame(a,b,c,e)
data_i = rbind(d, d_i)
data_i$iteration = i
results[[i]] <- data_i
}
results_df <- do.call(rbind.data.frame, results)
At the moment, these 100 datasets have all been placed in the same file ("results_df"). Now, I want to break the "results_df" file into each of these 100 datasets (using the "iteration" column as the index):
results_df$iteration = as.factor(results_df$iteration)
X<-split(results_df, results_df$iteration)
This "X" file seems to be a "list" with each of the 100 datasets listed as follows:
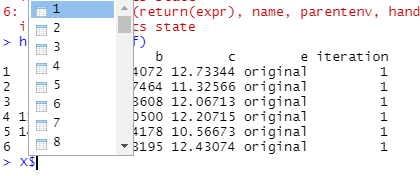
I can access each of these files by calling the "index" using i , e.g.
> head(X$`1`)
a b c e iteration
1 2.141495 3.984072 12.73344 original 1
2 8.769269 4.267464 11.32566 original 1
3 5.413573 2.823608 12.06713 original 1
4 11.710470 3.710500 12.20715 original 1
5 14.423155 2.944178 10.56673 original 1
6 6.886629 2.843195 12.43074 original 1
> head(X$`2`)
a b c e iteration
401 2.141495 3.984072 12.73344 original 2
402 8.769269 4.267464 11.32566 original 2
403 5.413573 2.823608 12.06713 original 2
404 11.710470 3.710500 12.20715 original 2
405 14.423155 2.944178 10.56673 original 2
406 6.886629 2.843195 12.43074 original 2
> head(X$`98`)
a b c e iteration
38801 2.141495 3.984072 12.73344 original 98
38802 8.769269 4.267464 11.32566 original 98
38803 5.413573 2.823608 12.06713 original 98
38804 11.710470 3.710500 12.20715 original 98
38805 14.423155 2.944178 10.56673 original 98
38806 6.886629 2.843195 12.43074 original 98
My Question: I now want to write another function which performs linear regression on each of these 100 datasets, saves the regression coefficients, and places them into a single file. I tried to write the code for this:
results_1 <- list()
for (i in 1:100){
model_i <- lm(a ~ b c, data = X$`i`)
coeff_i = model_i$coefficients
results_1[[i]] <- coeff_i
}
results_df_1 <- do.call(rbind.data.frame, results_1)
On first glance, this appears to have worked - but this is displaying all the regression coefficients as the same. This is impossible, seeing as the regression model was run 100 times on different datasets :
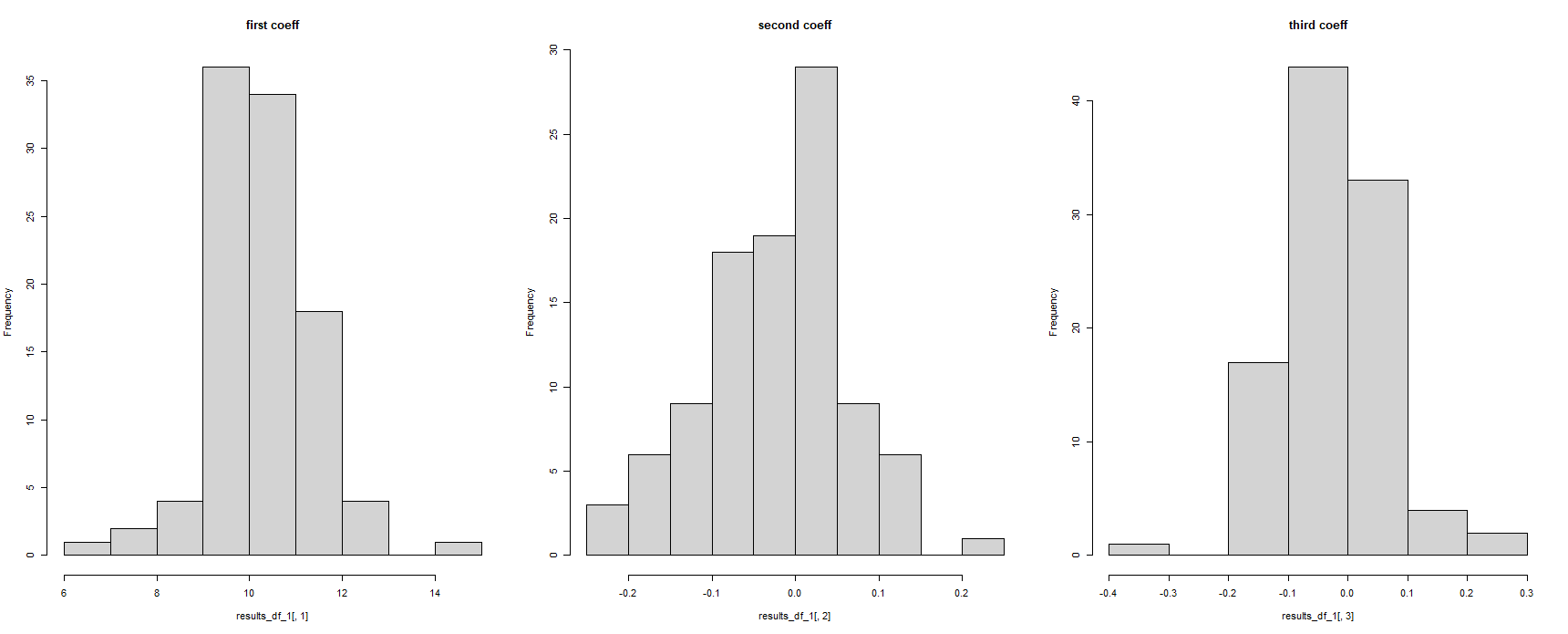
#for some reason, the column names have been corrupted
hist(results_df_1$c.14.5741211250235..14.5741211250235..14.5741211250235..14.5741211250235.., main = "first coeff")
hist(results_df_1$c..0.105285805666629...0.105285805666629...0.105285805666629.., main = "second coeff")
hist(results_df_1$c..0.236548691738492...0.236548691738492...0.236548691738492.., main = "third coeff")
Can someone please help me fix this problem? When you use the "split()" function in R, is this the correct way to "call" the "split components" in future commands ?
model_i <- lm(a ~ b c, data = X$`i`)
Thanks!
CodePudding user response:
I was able to fix this problem:
a = rnorm(300,10,5)
b = rnorm(300,3,1)
c = rnorm(300,12,1)
e = "original"
d = data.frame(a,b,c,e)
results <- list()
for (i in 1:100){
a = rnorm(100,10,10)
b = rnorm(100,10,10)
c = rnorm(100,10,10)
e = "simulated"
d_i = data.frame(a,b,c,e)
data_i = rbind(d, d_i)
data_i$iteration = i
results[[i]] <- data_i
}
results_df <- do.call(rbind.data.frame, results)
X<-split(results_df, results_df$iteration)
#####
results_1 <- list()
for (i in 1:100){
#here was the problem
model_i <- lm(a ~ b c, data = X[[i]])
coeff_i = model_i$coefficients
results_1[[i]] <- model_i$coefficients
}
results_df_1 <- do.call(rbind.data.frame, results_1)
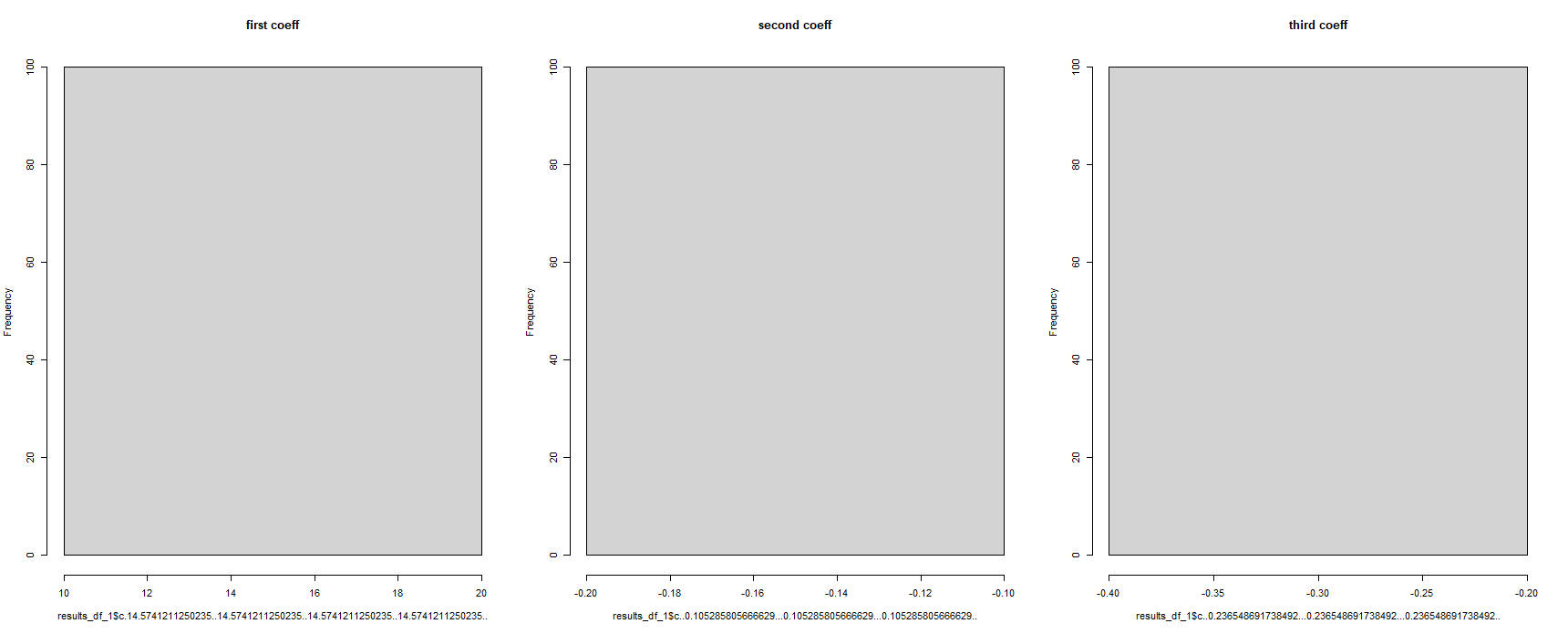
par(mfrow = c(1, 3))
hist(results_df_1[,1], main = "first coeff")
hist(results_df_1[,2], main = "second coeff")
hist(results_df_1[,3], main = "third coeff")