Given a string such as
cite{AA,BBB, C} skip{DD} cite{EE,F}
, I am trying to extract the comma-separated strings in the specific tag (in this case, named as cite) using Regex.
Thus, the output for the above string should result in
AA
BBB
C
EE
F
I think /cite{(. ?)}/ selects strings in \cite{....} form, but how do we then split the string in this output?
I find that some expressions like [^,(?! )] split the strings based on comma, but I cannot find a way to couple these two things.
CodePudding user response:
You could split on the comma using a lookbehind, checking for the cite{ prefix, for example:
But outside of using a programming language, I'm not sure how you would capture what you want if it's not fixed length, in a single regex. Though if it is fixed-width, you could do something like this:
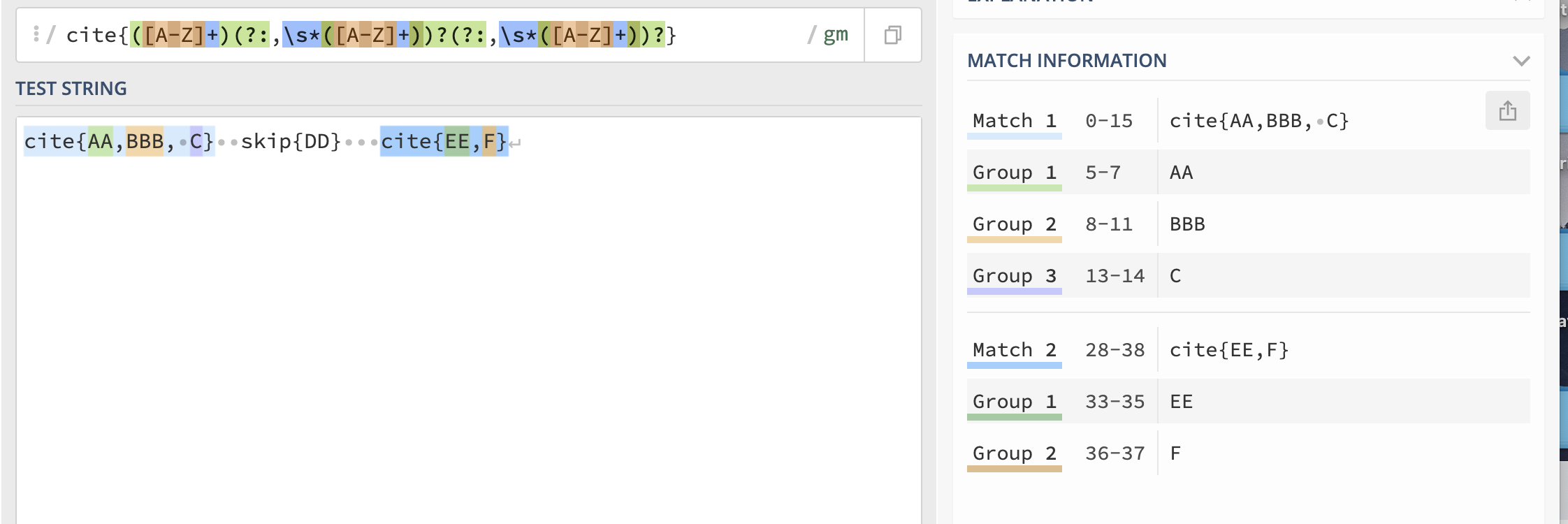
CodePudding user response:
Suppose the string were
cite{AA,BBB, C} skip{DD} GG cite{EE,F} ^^ ^^^ ^ ^^ ^We want to match the five substrings indicated by the carets.
If the regex engine supports variable-length lookbehinds we could use the regular expression
(?<=\bcite{[^{}]*?)[A-Z] (?=[^{}]*})Demo (click the "Context" tab at the link to see the matches).
This regex can be broken down as follows.
(?<= # begin a positive lookbehind \bcite # match literal preceded by a word break { # match character [^{}]*? # match zero or more chars other than braces, lazily ) # end positive lookbehind [A-Z] # match >= 1 uppercase letters (?= # begin positive lookahead [^{}]*? # match zero or more chars other than braces, then '}' ) # end positive lookahead