I can do a pandas styles heatmap over a multi-index no problem:
df = sns.load_dataset('geyser').reset_index()
df['3m_duration'] = df.duration > 3
group_cols = ['kind', '3m_duration']
count_gpby = df[
group_cols ['index']
].groupby(
group_cols
)
count_gpby.count().style.background_gradient(cmap ='Blues')
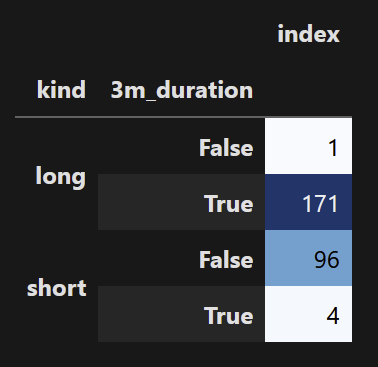
I can also divide a subset groupby by the total groupby to get a comparative rate/ratio per group:
df['binary'] = 'A'
df.loc[100:, 'binary'] = 'B'
subset_gpby = df[
group_cols ['index']
].loc[df.binary=='B'].groupby(
group_cols
).count()
(subset_gpby / gpby).style.background_gradient(cmap ='Blues')
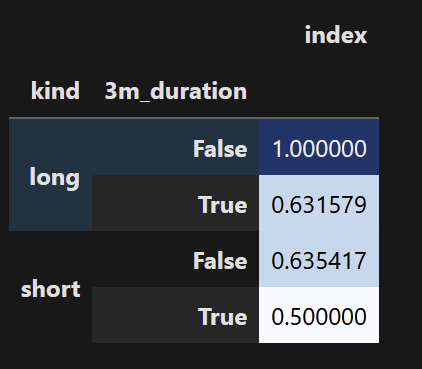
But then I try to combine these two "views" as two columns in the same multi-index dataframe so that I can see a raw count and a comparative ratio at the same time. This has no issue printing:
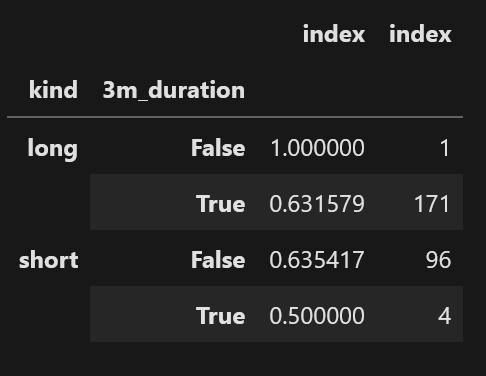
But it cant be displayed with the Pandas style heatmap background gradient because of "non-unique indices":
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-275-f82cbb6545e2> in <module>
----> 1 pd.concat([(subset_gpby / gpby), gpby], axis=1).style.background_gradient(cmap ='Blues')
C:\ProgramData\Anaconda3\envs\venv\lib\site-packages\pandas\core\frame.py in style(self)
959 from pandas.io.formats.style import Styler
960
--> 961 return Styler(self)
962
963 _shared_docs[
C:\ProgramData\Anaconda3\envs\venv\lib\site-packages\pandas\io\formats\style.py in __init__(self, data, precision, table_styles, uuid, caption, table_attributes, cell_ids, na_rep, uuid_len)
161 data = data.to_frame()
162 if not data.index.is_unique or not data.columns.is_unique:
--> 163 raise ValueError("style is not supported for non-unique indices.")
164
165 self.data = data
ValueError: style is not supported for non-unique indices.
However,
pd.concat([(subset_gpby / gpby), gpby], axis=1).index.value_counts()
> (short, False) 1
> (short, True) 1
> (long, True) 1
> (long, False) 1
> dtype: int64
shows that there's only one instance of each index, and the index is equal to the previous indices that render with no problem:
pd.concat([(subset_gpby / gpby), gpby], axis=1).index == (subset_gpby / gpby).index
> array([ True, True, True, True])
Why does this error appear?
CodePudding user response:
In pandas, both the "Index", and "Columns" are of type 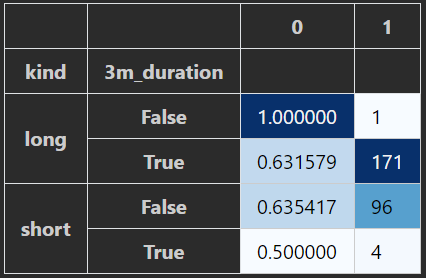
Setup used:
import pandas as pd
import seaborn as sns
# Setup Data
df = sns.load_dataset('geyser').reset_index()
group_cols = ['kind', '3m_duration']
df['3m_duration'] = df['duration'].gt(3)
subset_df = df[[*group_cols, 'index']].copy()
# Build Count DataFrames
gpby = subset_df.groupby(group_cols).count()
subset_gpby = subset_df.loc[100:, :].groupby(group_cols).count()