I have a subset of the dataframe
df = pd.DataFrame(
{
'id': ['1001','1002','1003','1004','1005','1006','1007','1008','1009','1010'],
'colA': ['H','L B','L H','L B','L S B','B','B S L','L B S','L S B','L S B'],
'colB': ['H','L|B','H|L','H|L','L|S|B','L|S|B','L|S|B','L|S|B','L|S','L']
}
)
I'm doing row level comparison for this dataframe. I want to check whether all the letters in row['colA'] match with all the letters in row['colB'], regardless of what order they appear and ignoring the | in colB. This is the logic for the function, but it doesn't work as intended and how do I update it to ignore |
def match_or_not(df):
for index,row in df.iterrows():
if row['colA'] == row['colB']:
print ("Match for " str(row['id']))
else:
print ("Not match for " str(row['id']))
I need help to update the condition following the if keyword in the above function, how can I write to get desire output. The cases for which it should match and not match are shown in the picture:
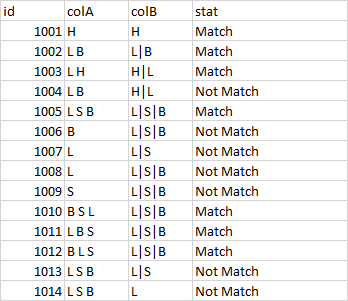
CodePudding user response:
The following should work:
def match_or_not(df):
for index,row in df.iterrows():
#First make a list out of the values, then compare the sorted values
if sorted(row['colA'].split(" ")) == (sorted(row['colB'].split("|"))):
print ("Match for " str(row['id']))
else:
print ("Not match for " str(row['id']))
CodePudding user response:
You could make use of the "split()" method for strings, as well as sets, like this:
def match_or_not(df):
for index,row in df.iterrows():
a_set = set(row['colA'].split(" "))
b_set = set(row['colB'].split("|"))
if a_set == b_set:
print ("Match for " str(row['id']))
else:
print ("Not match for " str(row['id']))
split() creates a list of substrings using a given delimiter (in your case a space and a |).
set() makes that list a set. Sets are easy to compare, as order does not matter within them. However this solution does come with a potential drawback, which is not reflected in your example data:
set("L L".split(" "))
This splits the string L L which creates a list of two strings 'L'.
However, a sets elements are unique, so it gets converted to the set {'L'} (mind only one L.)
So if your data is expected to contain such double strings and their occurrence is intended to match by amount, this solution does not suffice.
CodePudding user response:
You can use df.apply without df.iterrows():
>>> df.apply(lambda row: f"Match for {row['id']}" if set(row['colA'].replace(" ", "")) == set(row['colB'].replace("|", "")) else f"No match for {row['id']}", axis=1)
0 Match for 1001
1 Match for 1002
2 Match for 1003
3 No match for 1004
4 Match for 1005
5 No match for 1006
6 Match for 1007
7 Match for 1008
8 No match for 1009
9 No match for 1010
The set(row['colA'].replace(" ", "")) == set(row['colB'].replace("|", "")) condition makes sure all chars but spaces from colA exist in colB (other than | chars, all the spaces and pipes are removed before converting to a set).