Below is my dataframe(df), where i have instances at a weekly level of expected and actuals
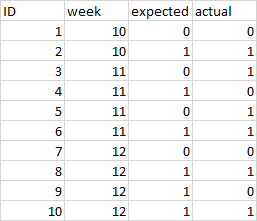
I need to apply the below Python code function to calculate the auc at a cumulative weekly level.
from sklearn.metrics import roc_auc_score
def auc_group(df):
y_hat = df.expected
y = df.actual
return (roc_auc_score(y,y_hat))
For each week, the scoring should happen for all records until that week, so that result should look something like below.
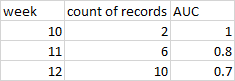
While it is simple to apply the function for each week, applying that to do a cumulative score, considering all the records until that week, has been a challenge for me. Any help in solving this is appreciated.
CodePudding user response:
If need cumulative count and cumulative roc_auc_score use:
from sklearn.metrics import roc_auc_score
s1 = df['week'].value_counts().sort_index().cumsum()
expected, actual = [],[]
def f(x):
expected.extend(x['expected'].tolist())
actual.extend(x['actual'].tolist())
return roc_auc_score(actual, expected)
s2 = df.groupby('week').apply(f)
df = (pd.concat([s1, s2], axis=1, keys=('count of records','AUC'))
.rename_axis('week')
.reset_index())
print (df)
week count of records AUC
0 10 2 1.000000
1 11 6 0.500000
2 12 10 0.583333
If need cumulative count and roc_auc_score per groups (not cumulative) use:
from sklearn.metrics import roc_auc_score
s1 = df['week'].value_counts().sort_index().cumsum()
s2 = df.groupby('week').apply(lambda x: roc_auc_score(x.actual,x.expected))
df = (pd.concat([s1, s2], axis=1, keys=('count of records','AUC'))
.rename_axis('week')
.reset_index())
print (df)
week count of records AUC
0 10 2 1.000000
1 11 6 0.166667
2 12 10 0.750000
CodePudding user response:
import pandas as pd
import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
data = pd.concat([pd.DataFrame(iris.target, columns = ['target']),
pd.DataFrame(iris.data, columns = iris.feature_names)], axis = 1)
def target_replace(x):
for i in [0,1,2]:
if x == i:
return(iris.target_names[i])
data.target = data.target.apply(target_replace)