I got a large dataset which is the imported schedule (spanning multiple years) for my team. I cleaned the data (made it long instead of wide), however I encounter a problem.
First an explanation of the data:
- 'year' and 'period' are obtained from the split sheetname. Both strings.
- 'week' the week of the year, obtained from the roster. Float.
- 'date' converted from string, for which I wrote a function as the dates were in Dutch and needed to be normalized, no year was defined so therefore the year from the first column is used. After processing; datetime format.
- 'shift' the type of shift it belongs to. S1 > early, S2 > late, S3 > night.
- Each rule is assigned to one of my employees, those names are erased for privacy reasons.
- I've written a class with several methods that apply rules our government enforces on schedules.
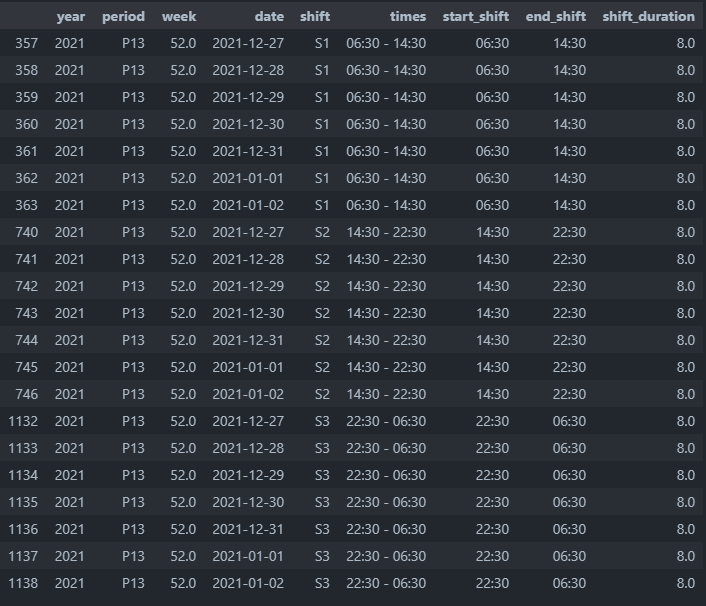
Now my problem:
As you can see: entries 1137 and 1138 should belong to the year 2022. But how do I change this easily? I tried:
for week, date in prepocessed_data_merged[['week', 'date']].values:
# There are always more than 52 weeks in a year.
# If the month of the date in week 52 is 1 (Jan), then something is wrong.
if (week == 52) & (date.month == 1):
prepocessed_data_merged.loc[(prepocessed_data_merged['week'] == week)
& (prepocessed_data_merged['date']), 'date'] = ???
But as you might expect this returns a series since there are three shifts on a day, so three entries of a date that need their year changed. So, how does one change the year of a selected series/slice, simultaneously changing it in the dataframe?
I know I can use: dt.replace(year=current_year 1) but how do I enforce this replace on this selected series in the preprocessed_data DF? Thanks in advance!
CodePudding user response:
Have you tried:
cond = prepocessed_data_merged['week'].eq(52) & prepocessed_data_merged['date'].dt.month.eq(1)
prepocessed_data_merged.loc[cond, 'date'] = pd.DateOffset(years=1)
CodePudding user response:
I applied the code below, which solved my problem. If there are suggestions for making this code simpler, please do! I like to learn.
for week, date in prepocessed_data_merged[['week', 'date']].values:
# There are always more than 52 weeks in a year.
# If the month of the date in week 52 is 1 (Jan), something is wrong.
if (week >= 52) & (date.month == 1):
cond = (prepocessed_data_merged['week'] == week) & (prepocessed_data_merged['date'] == date)
idx = prepocessed_data_merged[cond].index
for i in idx:
prepocessed_data_merged.loc[i, 'date'] = date.replace(year=date.year 1)
# If the month of the date is 12 (Dec) and the week is 1, something is wrong.
if (week == 1) & (date.month == 12):
cond = (prepocessed_data_merged['week'] == week) & (prepocessed_data_merged['date'] == date)
idx = prepocessed_data_merged[cond].index
for i in idx:
prepocessed_data_merged.loc[i, 'date'] = date.replace(year=date.year-1)