I have a column with dictionaries, keys of dictionaries are randomly ordered, dictionaries may contain different amount of keys (starting from 0) My goal is to sort keys in each row and then pivot them, to make keys column headers and store its` values accordingly.
I made my way from raw data and unpacking from json to writing it into df, and now I`m stuck
A few examples:
{'key_b': 40, 'key_d': 1, 'key_e': 15, 'key_h': 11, 'key_f': 15, 'key_a': 273, 'key_c': 9}
{'key_c': 10, 'key_a': 286, 'key_b': 42}
{'key_f': 1}
{'key_g': 'trial', 'key_i': 1}
{'key_d': 1, 'key_e': 3, 'key_h': 2, 'key_i': 1, 'key_c': 11, 'key_b': 47, 'key_a': 325, 'key_g': 'premium'}
{'key_g': 'trial'}
And I want it to have the next appearance:
key_a key_b key_c key_d key_e key_f key_g key_h key_i
273 40 null 1
325 42 9 null etc
286 41 9 10`
CodePudding user response:
input:
import pandas as pd
df = pd.DataFrame({"Dict Column": [
{'key_b': 40, 'key_d': 1, 'key_e': 15, 'key_h': 11, 'key_f': 15, 'key_a': 273, 'key_c': 9},
{'key_c': 10, 'key_a': 286, 'key_b': 42},
{'key_f': 1},
{'key_g': 'trial', 'key_i': 1},
{'key_d': 1, 'key_e': 3, 'key_h': 2, 'key_i': 1, 'key_c': 11, 'key_b': 47, 'key_a': 325, 'key_g': 'premium'},
{'key_g': 'trial'}
]})
df = pd.json_normalize(df['Dict Column'])
print(df)
output:
key_b key_d key_e key_h key_f key_a key_c key_g key_i
0 40.0 1.0 15.0 11.0 15.0 273.0 9.0 NaN NaN
1 42.0 NaN NaN NaN NaN 286.0 10.0 NaN NaN
2 NaN NaN NaN NaN 1.0 NaN NaN NaN NaN
3 NaN NaN NaN NaN NaN NaN NaN trial 1.0
4 47.0 1.0 3.0 2.0 NaN 325.0 11.0 premium 1.0
5 NaN NaN NaN NaN NaN NaN NaN trial NaN
CodePudding user response:
You can do the following,
Create the dataframe from the dictionaries (I hope you have a column with dictionaries. You can convert the column into a list of dictionaries and then create a dataframe).
Drop duplicates
Sort them
dict1 = {'key_b': 40, 'key_d': 1, 'key_e': 15, 'key_h': 11, 'key_f': 15, 'key_a': 273, 'key_c': 9} dict2 = {'key_c': 10, 'key_a': 286, 'key_b': 42} dict3 = {'key_f': 1} dict4 = {'key_g': 'trial', 'key_i': 1} dict5 = {'key_d': 1, 'key_e': 3, 'key_h': 2, 'key_i': 1, 'key_c': 11, 'key_b': 47, 'key_a': 325, 'key_g': 'premium'} dict6 = {'key_g': 'trial'} lis = [dict1, dict2, dict3, dict4, dict5, dict6] df = pd.DataFrame() result = pd.DataFrame() for i in range(len(lis)-1): df = pd.DataFrame(data = lis[i], index = range(len(lis[i]))).drop_duplicates().append(pd.DataFrame(data = lis[i 1], index = range(len(lis[i 1]))).drop_duplicates()) result = result.append(df) result = result.drop_duplicates() result = result.reindex(sorted(result.columns), axis = 1) result
This will give the following result:
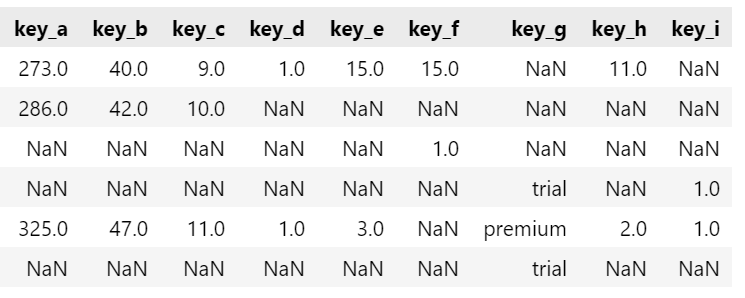
CodePudding user response:
With
df = pd.DataFrame(
{
'col': [
{'key_b': 40, 'key_d': 1, 'key_e': 15, 'key_h': 11, 'key_f': 15, 'key_a': 273, 'key_c': 9},
{'key_c': 10, 'key_a': 286, 'key_b': 42},
{'key_f': 1},
{'key_g': 'trial', 'key_i': 1},
{'key_d': 1, 'key_e': 3, 'key_h': 2, 'key_i': 1, 'key_c': 11, 'key_b': 47, 'key_a': 325, 'key_g': 'premium'},
{'key_g': 'trial'}
]
}
)
you could do
df = pd.DataFrame(df.col.to_list()).sort_index(axis=1)
Result:
key_a key_b key_c key_d key_e key_f key_g key_h key_i
0 273.0 40.0 9.0 1.0 15.0 15.0 NaN 11.0 NaN
1 286.0 42.0 10.0 NaN NaN NaN NaN NaN NaN
2 NaN NaN NaN NaN NaN 1.0 NaN NaN NaN
3 NaN NaN NaN NaN NaN NaN trial NaN 1.0
4 325.0 47.0 11.0 1.0 3.0 NaN premium 2.0 1.0
5 NaN NaN NaN NaN NaN NaN trial NaN NaN
CodePudding user response:
Cause there is no additional info in your question, how the data frame looks like - I start in my example with a series of the data frame that contains your dicts to explain the steps. See full example at the end.
pd.DataFrame([dict(sorted(x.items())) for x in pd.Series(d)])
Pick your Series
pd.Series(d)Iterate and sort it:
[dict(sorted(x.items())) for x in pd.Series(d)]Create a data frame
pd.DataFrame([dict(sorted(x.items())) for x in pd.Series(d)])
Additionally you would concat it to your original data Frame.
pd.concat([ORIGINAL_DF, NEW_DF], axis=1)
Example
import pandas as pd
d = [{'key_b': 40, 'key_d': 1, 'key_e': 15, 'key_h': 11, 'key_f': 15, 'key_a': 273, 'key_c': 9},
{'key_c': 10, 'key_a': 286, 'key_b': 42},
{'key_f': 1},
{'key_g': 'trial', 'key_i': 1},
{'key_d': 1, 'key_e': 3, 'key_h': 2, 'key_i': 1, 'key_c': 11, 'key_b': 47, 'key_a': 325, 'key_g': 'premium'},
{'key_g': 'trial'}]
pd.DataFrame([dict(sorted(x.items())) for x in pd.Series(d)])
Outpout
| key_a | key_b | key_c | key_d | key_e | key_f | key_h | key_g | key_i |
|---|---|---|---|---|---|---|---|---|
| 273.0 | 40.0 | 9.0 | 1.0 | 15.0 | 15.0 | 11.0 | ||
| 286.0 | 42.0 | 10.0 | ||||||
| 1.0 | ||||||||
| trial | 1.0 | |||||||
| 325.0 | 47.0 | 11.0 | 1.0 | 3.0 | 2.0 | premium | 1.0 | |
| trial |
Example (incl. data frame)
import pandas as pd
df = pd.DataFrame(
{
'col1':[1,2,3,4,5,6],
'coldicts':[{'key_b': 40, 'key_d': 1, 'key_e': 15, 'key_h': 11, 'key_f': 15, 'key_a': 273, 'key_c': 9},
{'key_c': 10, 'key_a': 286, 'key_b': 42},
{'key_f': 1},
{'key_g': 'trial', 'key_i': 1},
{'key_d': 1, 'key_e': 3, 'key_h': 2, 'key_i': 1, 'key_c': 11, 'key_b': 47, 'key_a': 325, 'key_g': 'premium'},
{'key_g': 'trial'}
]
}
)
pd.concat([df,pd.DataFrame([dict(sorted(x.items())) for x in df.coldicts])], axis=1)
| col1 | coldicts | key_a | key_b | key_c | key_d | key_e | key_f | key_h | key_g | key_i |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | {'key_b': 40, 'key_d': 1, 'key_e': 15, 'key_h': 11, 'key_f': 15, 'key_a': 273, 'key_c': 9} | 273.0 | 40.0 | 9.0 | 1.0 | 15.0 | 15.0 | 11.0 | ||
| 2 | {'key_c': 10, 'key_a': 286, 'key_b': 42} | 286.0 | 42.0 | 10.0 | ||||||
| 3 | {'key_f': 1} | 1.0 | ||||||||
| 4 | {'key_g': 'trial', 'key_i': 1} | trial | 1.0 | |||||||
| 5 | {'key_d': 1, 'key_e': 3, 'key_h': 2, 'key_i': 1, 'key_c': 11, 'key_b': 47, 'key_a': 325, 'key_g': 'premium'} | 325.0 | 47.0 | 11.0 | 1.0 | 3.0 | 2.0 | premium | 1.0 | |
| 6 | {'key_g': 'trial'} | trial |