When calculating a mean in two different ways (on a dataframe and on the same pivoted dataframe) I expect the outcomes to be identical. However, they appear to differ. Am I missing something?
Here's the dataset:
import pandas as pd # pandas version is 1.3.4
df = pd.read_csv(
'https://data.rivm.nl/covid-19/COVID-19_aantallen_gemeente_per_dag.csv',
usecols = ['Date_of_publication', 'Municipality_code', 'Municipality_name', 'Province', 'Total_reported', 'Hospital_admission', 'Deceased'],
parse_dates = ['Date_of_publication'],
index_col = ['Date_of_publication'],
sep = ';'
).dropna()
df.tail()

I would like to calculate a mean per Date_of_publication of the column Total_reported.
Method 1:
df.Total_reported.groupby(df.index).mean()
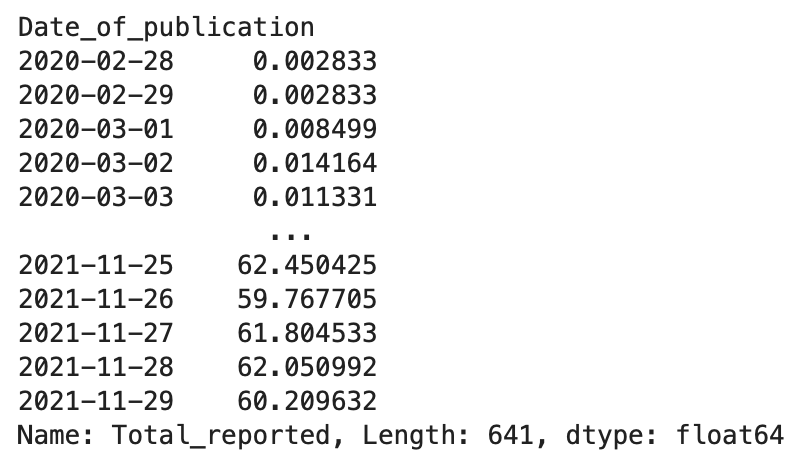
Method 2:
df_pivot = pd.pivot_table(
df.reset_index(),
values='Total_reported',
index='Date_of_publication',
columns='Municipality_name'
)
df_pivot.mean(axis=1)
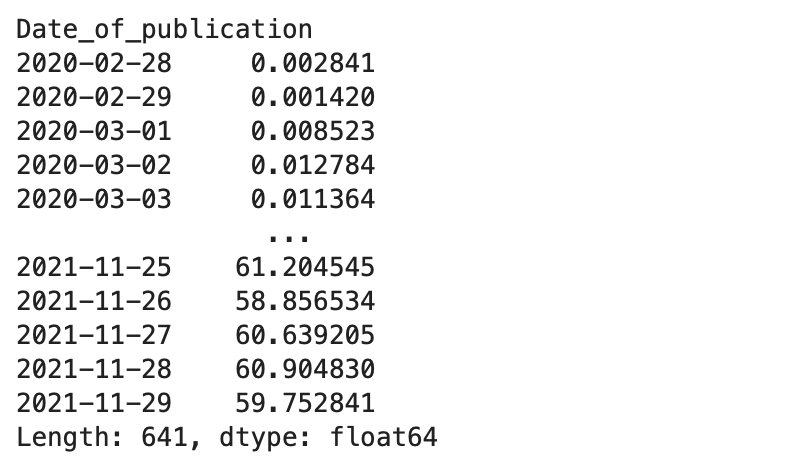
CodePudding user response:
Since I cannot post a code example as a comment, I want to leverage on @mozway's answer that the reason is duplicates in the columns when doing a pivot_table
df = pd.DataFrame({"total":[50,10,30,15,10,5],"state":["UC","FI","DK","LM","NA","PL"]},index=["2021-11-29"]*3 ["2021-11-30"]*3)
df.index.name = "date"
print(df) #No duplicated "state"
# total state
#date
#2021-11-29 50 UC
#2021-11-29 10 FI
#2021-11-29 30 DK
#2021-11-30 15 LM
#2021-11-30 10 NA
#2021-11-30 5 PL
df["total"].groupby(df.index).mean()
#2021-11-29 30.0
#2021-11-30 10.0
pd.pivot_table(df.reset_index(),index="date",values="total",columns="state").mean(axis=1)
#2021-11-29 30.0
#2021-11-30 10.0
as seen, it gives the same result but when we change the PL to NA in the state i.e we now have 2xNA the result for the pivot_table is changed
df = pd.DataFrame({"total":[50,10,30,15,10,5],"state":["UC","FI","DK","LM","NA","NA"]},index=["2021-11-29"]*3 ["2021-11-30"]*3) #changed the 'PL' 'NA'
#2021-11-29 30.00
#2021-11-30 11.25 #was 10.0 before