so I have this data to be used for training a model. There are some values in certain columns labeled as unknown. Assumed that it would be missing values.
I am also given a set of queries/testing data, and these queries also has unknown values.
A few example data, the training set:
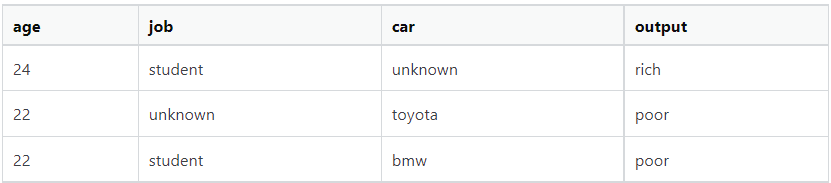
the query for prediction:

I thought to do imputations based on the percentage of the missing values (unknown) in the training set. However, the queries contains some unknown values too. What would be the best approach? Isit okay to consider the unknown values a category too?
CodePudding user response:
There is no general "best approach" for handling missing values. You already listed two of the common ones: imputation and considering "missing" as an additional class. Both are "okay" and which one is more suitable depends on the scenario.
In your case I can imagine missingness actually being informative (e.g. maybe unemployed people or people with a low-paid job are more likely to have missing values for the job feature, due to fear of social stigmatisation ?).
In this case making the missings an additional class might be a good approach.
Note that some of the common gradient boosting libraries like lightgbm, xgboost can handle missing values by default so you could try one of those for your dataset.