This code will create a figure of ecdf where the curve of number 5 represents the truth.
library(data.table)
library(ggplot2)
set.seed(123)
dat_data <- data.table(meanval = rnorm(10),
sdval = runif(10, 0.5, 3),
rep = sample.int(1000, 10))
dat <- rbindlist(lapply(1:dim(dat_data)[1],
function(x) data.table(rowval = x, dist = rnorm(dat_data[x,
rep],dat_data[x, meanval], dat_data[x, sdval]))))
ggplot(dat, aes(x = dist, group = factor(rowval), color =
factor(rowval)))
stat_ecdf(size = 2)
based on the outputs of the ecdf,I would like to rank the numbers from closest to 5 to furthest from 5.
CodePudding user response:
Here's a thought for ranking them.
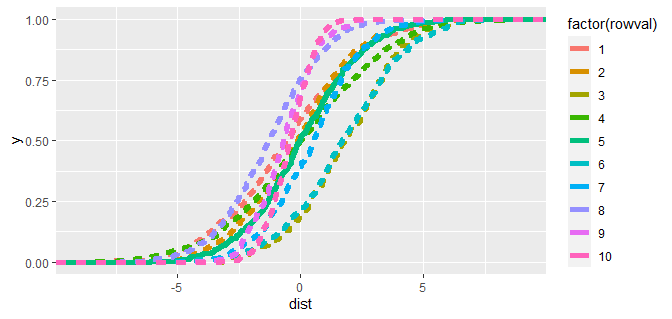
First, for reference, I plotted it but added linetype= so I could more easily see 5:
library(ggplot2)
ggplot(dat, aes(x = dist, group = factor(rowval), color = factor(rowval), linetype = rowval != 5))
stat_ecdf(size = 2)
scale_linetype_discrete(guide = FALSE)
Using data.table, I'll measure the difference at 51 points (every 0.02) along their quantiles:
library(data.table)
quants <- seq(0, 1, length.out = 51)
datquants <- dat[, .(quant = quants, val = ecdf(dist)(quantile(dist, quants))), by = rowval]
datquants
# rowval quant val
# <int> <num> <num>
# 1: 1 0.00 0.001540832
# 2: 1 0.02 0.020030817
# 3: 1 0.04 0.040061633
# 4: 1 0.06 0.060092450
# 5: 1 0.08 0.080123267
# 6: 1 0.10 0.100154083
# 7: 1 0.12 0.120184900
# 8: 1 0.14 0.140215716
# 9: 1 0.16 0.160246533
# 10: 1 0.18 0.180277350
# ---
# 501: 10 0.82 0.819905213
# 502: 10 0.84 0.840047393
# 503: 10 0.86 0.859004739
# 504: 10 0.88 0.879146919
# 505: 10 0.90 0.899289100
# 506: 10 0.92 0.919431280
# 507: 10 0.94 0.939573460
# 508: 10 0.96 0.959715640
# 509: 10 0.98 0.979857820
# 510: 10 1.00 1.000000000
(Note: a previous version of this answer did not use ecdf, which would be exposed/wrong if the range within each rowval were not the same. Using ecdf, all of our area calcs are in the same domain.)
From here, we separate the 5 quantiles, join it back in based on quant, find the absolute difference, then summarize.
datquants[rowval == 5, .(quant, val5 = val)
][datquants, on = .(quant)
][, val := abs(val - val5)^2
][, .(area = 1e6*sum(val)), by = rowval
][, rank := rank(area) ]
# rowval area rank
# <int> <num> <num>
# 1: 1 22.45959 7
# 2: 2 18.93004 4
# 3: 3 160.48164 10
# 4: 4 17.66167 2
# 5: 5 0.00000 1
# 6: 6 21.52974 6
# 7: 7 24.35520 8
# 8: 8 18.48263 3
# 9: 9 59.90059 9
# 10: 10 19.78913 5
I think the sum-of-squares (of differences) is a good measure, not sure if it is the best. (The 1e6* is merely to bring the numbers into a non-scientific-notation realm for easy visual comparison.)
Disclaimer: this is one method, perhaps just a heuristic since I'm not certain it's the only or best way.