I have a dataframe (small sample shown below, it has more columns), and I want to find the column names with the minimum values.
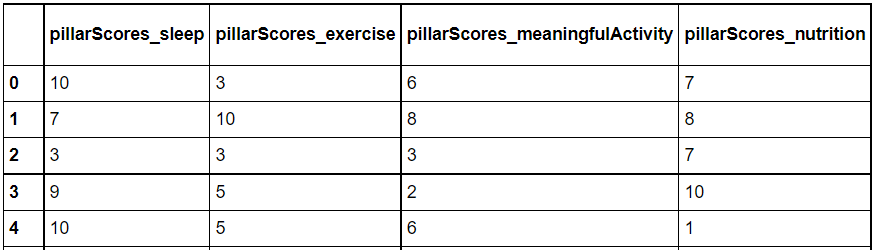
Right now, I have the following code to deal with it:
finaldf['min_pillar_score'] = finaldf.iloc[:, 2:9].idxmin(axis="columns")
This works fine, but does not return multiple values of column names in case there is more than one instance of minimum values. How can I change this to return multiple column names in case there is more than one instance of the minimum value?
Please note, I want row wise results, i.e. minimum column names for each row.
Thanks!
CodePudding user response:
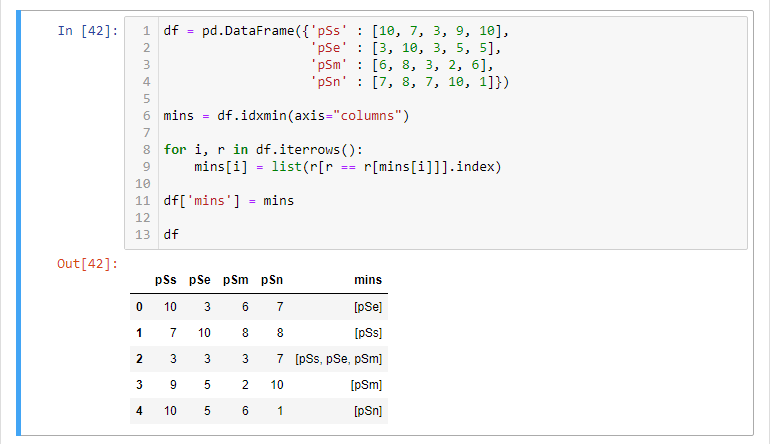
try the code below and see if it's in the output format you'd anticipated. it produces the intended result at least.
result will be stored in mins.
mins = df.idxmin(axis="columns")
for i, r in df.iterrows():
mins[i] = list(r[r == r[mins[i]]].index)
CodePudding user response:
Assuming this input as df:
A B C D
0 5 8 9 5
1 0 0 1 7
2 6 9 2 4
3 5 2 4 2
4 4 7 7 9
You can use the underlying numpy array to get the min value, then compare the values to the min and get the columns that have a match:
s = df.eq(df.to_numpy().min()).any()
list(s[s].index)
output: ['A', 'B']