I am scraping a web page and getting a list of authors with their rates. saved the data in a .csv file and now would like to process the gathered data and create a top list of the most rated 5 authors.
here is how the .csv file look like:
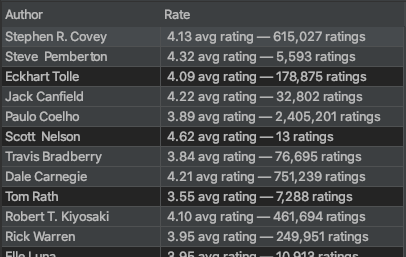
Here is what I have done so far:
import csv
with open ('goodreads-book.csv', 'r') as csv_file:
csv_reader = csv.reader(csv_file)
next(csv_reader)
with open("TopFiveRatedAuthors.csv", 'w') as new_file:
for line in csv_reader:
rate = line[1]
rate = rate[19:-8]
# print(rate)
if (rate) > ('100,000'):
# print (rate)
t =line
csv_writer = csv.writer(new_file)
csv_writer.writerow(line)
and my question is on line:
if str(rate) > '100,000':
right now it returns some random cells, however, I would like to write a code here to compare the cells dynamically and only return the top highest rated. I am quite new to this topic and I would really appreciate any help.
CodePudding user response:
Because of the way Python compares strings, trying to compare numerical strings will not always work. Example: '10000' > '900' will return False. If you want to compare the strings, convert them to numbers with something like:
rate = rate[19:-8]
rate = int(rate.replace(',','')) #get rid of commas before conversion
if rate > 100000: #compare integers
CodePudding user response:
You could probably split the Rate columns on spaces. The 5th part should be the rating. Then remove the , and convert to an integer. For example:
import csv
with open ('goodreads-book.csv', 'r') as f_input, open('TopFiveRatedAuthors.csv', 'w', newline='') as f_output:
csv_input = csv.reader(f_input)
header = next(csv_input)
csv_output = csv.writer(f_output)
csv_output.writerow(header) # copy header to output
for row in csv_input:
rating = int(row[1].split(' ')[4].replace(',', ''))
if rating > 100000:
csv_output.writerow(row)
You need to put a textual version of your CSV file into your question to allow it to be tested. If there is a problem, add print(row) to see which row it fails on and then also print(row[1].split(' ')) to see if it is splitting correctly.
For example 4.13 avg rating -- 615,027 ratings should be split into the list:
['4.13', 'avg', 'rating', '--', '615,027', 'ratings']
So [4] is needed for the number.