I have created a new dataframe by doing operations on two others and I would like to remove the false in the new dataframe but it is noted that my information is only in one column and I do not know how to do it.
 code
code
import pandas as pd
members = pd.read_csv("https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-09-22/members.csv")
expeditions = pd.read_csv("https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-09-22/expeditions.csv")
success_members_exp = pd.merge(members,
expeditions[['expedition_id','termination_reason']], on='expedition_id', how='inner')
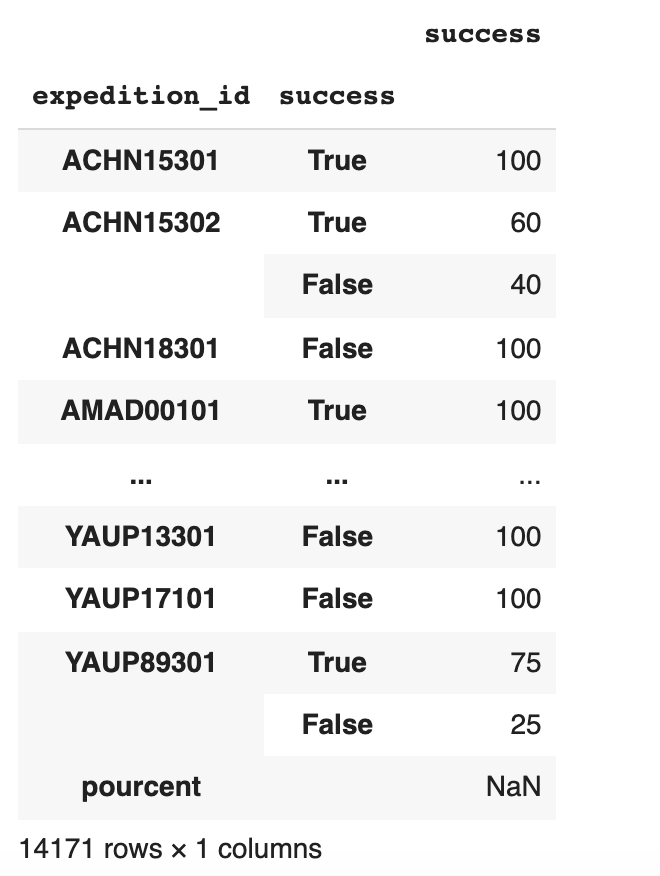
success_members_exp_pourcent["pourcent"] = success_members_exp.groupby('expedition_id')['success'].value_counts(normalize=True) * 100
success_members_exp_pourcent.to_frame()
CodePudding user response:
Change:
success_members_exp_pourcent["pourcent"] = success_members_exp.groupby('expedition_id')['success'].value_counts(normalize=True) * 100
to:
s = (success_members_exp.groupby('expedition_id')['success']
.value_counts(normalize=True)
.rename('pourcent')
.mul(100))
success_members_exp_pourcent = success_members_exp.join(s, on=['expedition_id','success'])
Explanation:
Output s is Series with MultiIndex, so for new column use DataFrame.join with rename and multiple by 100.
CodePudding user response:
Which column is your information stored in? What type of column is it? We are missing a lot of context, a print out of the column would be really nice, with a more specific explanation of what exactly you are trying to extract.