I need advanced python pandas help for my problem. I have such a dataframe which contains 4 string columns that identify the hierarchy of the item and the rest are columns that follow the following pattern:
Text | Period (example: "ACTUAL | 2020-08-01")
Text can be either: Actual, Forecast t-1 or Forecast t-3. Period can be any month-year: 2020-08-01 .... For example: "ACTUAL | 2020-08-01" "FORECAST T-1 | 2020-08-01" "FORECAST T-3 | 2020-08-01"
df.columns
show as:
['HIERARCHY 1', 'HIERARCHY 2', 'HIERARCHY 3',
'ITEM NUMBER', 'ACTUAL|2020-06-01', 'ACTUAL|2020-07-01',
'ACTUAL|2020-08-01', 'ACTUAL|2020-09-01', 'ACTUAL|2020-10-01',
'ACTUAL|2020-11-01', 'ACTUAL|2020-12-01', 'ACTUAL|2021-01-01',
'ACTUAL|2021-02-01', 'ACTUAL|2021-03-01', 'ACTUAL|2021-04-01',
'ACTUAL|2021-05-01', 'ACTUAL|2021-06-01', 'ACTUAL|2021-07-01',
'ACTUAL|2021-08-01', 'ACTUAL|2021-09-01', 'ACTUAL|2021-10-01',
'FORECAST T-1|2021-01-01', 'FORECAST T-1|2021-08-01',
'FORECAST T-1|2021-09-01', 'FORECAST T-1|2021-10-01',
'FORECAST T-1|2021-11-01', 'FORECAST T-3|2021-03-01',
'FORECAST T-3|2021-10-01', 'FORECAST T-3|2021-11-01',
'FORECAST T-3|2021-12-01', 'FORECAST T-3|2022-01-01',
'FORECAST T-1|2020-07-01', 'FORECAST T-1|2020-08-01',
'FORECAST T-1|2020-09-01', 'FORECAST T-1|2020-10-01',
'FORECAST T-1|2020-11-01', 'FORECAST T-1|2020-12-01',
'FORECAST T-1|2021-02-01', 'FORECAST T-1|2021-03-01',
'FORECAST T-1|2021-04-01', 'FORECAST T-1|2021-05-01',
'FORECAST T-1|2021-06-01', 'FORECAST T-3|2020-09-01',
'FORECAST T-3|2020-10-01', 'FORECAST T-3|2020-11-01',
'FORECAST T-3|2020-12-01', 'FORECAST T-3|2021-01-01',
'FORECAST T-3|2021-02-01', 'FORECAST T-3|2021-04-01',
'FORECAST T-3|2021-05-01', 'FORECAST T-3|2021-06-01',
'FORECAST T-3|2021-07-01', 'FORECAST T-3|2021-08-01'],
For any period we can have either: Actual, Forecast t-1 or Forecast t-3. There is no guarantee that there are the three of them present. Maybe only one of them, for example for specific period we can have only: "ACTUAL | 2020-08-01", "FORECAST T-1 | 2020-08-01", but there is no column showing: "FORECAST T-3 | 2020-08-01".

My goal is to achieve the following dataframe:


First step 1:
Re-order the column names as follows:
df.columns
should be: ACTUAL | Period 1 .... ACTUAL | Period N, where N is the last period Followed by FORECAST T-1 | Period 1 .... FORECAST T-1 | Period N, where N is the last period Lastly, FORECAST T-3 | Period 1 .... FORECAST T-3 | Period N, where N is the last period
It should be ordered by: Actual, Forecast t-1 and lastly Forecast t-3. Within each category, it should be from oldest period to most recent (left to right).
Step 2:
I want to perform operations for columns that belong to the same period. I want to loop through each of the periods within the column names, and for each period, I want to see if there is column: "ACTUAL | Any Period (ex. 2020-08-01)" and Forecast metrics for that periods, if there are: then I want to compute the absolute error, which would be computed as:
df["ABS ERROR T-1 | 2020-08-01"] = (df["ACTUAL | 2020-08-01"] - df["FORECAST T-1 | 2020-08-01"]).abs()
df["ABS ERROR T-3 | 2020-08-01"] = (df["ACTUAL | 2020-08-01"] - df["FORECAST T-3 | 2020-08-01"]).abs()
If there is no ACTUAL in the current period, then skip. If there is no FORECAST (either T-1 or T-3), then skip the period as well.
If there is at least ACTUAL and 1 Forecast period then compute the Absolute Error.
Then, put it on the dataframe at the end as a new column. I have more than 50 columns. I cannot do this manually so I need to find a pattern for my problem.
CodePudding user response:
Your column names having dates in them makes your dataframe hard to read. I would suggest restructuring your data in order to have dates as index.
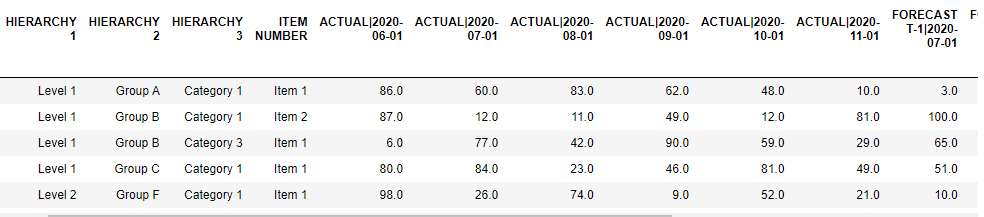
Assuming you start with the following dataframe:
HIERARCHY 1 HIERARCHY 2 HIERARCHY 3 ITEM NUMBER ACTUAL|2020-06-01 ... FORECAST T-3|2021-04-01 FORECAST T-3|2021-05-01 FORECAST T-3|2021-06-01 FORECAST T-3|2021-07-01 FORECAST T-3|2021-08-01
0 Level 1 Group A Category 1 Item 1 30 ... 64 91 100 34 87
1 Level 1 Group B Category 1 Item 2 88 ... 20 118 22 97 90
2 Level 2 Group F Category 1 Item 2 91 ... 88 46 116 50 59
I would first split the column names and add date as index. This way you create several dataframes for each ['HIERARCHY 1', 'HIERARCHY 2', 'HIERARCHY 3','ITEM NUMBER', 'date'] combination. You can then concatenate those dataframes:
result_df = []
for col in df.columns:
if '|' in col:
name, date = col.split('|')
df_res = df[['HIERARCHY 1', 'HIERARCHY 2', 'HIERARCHY 3','ITEM NUMBER', col]]
df_res = df_res.rename(columns={col:name})
df_res['date'] = date
result_df.append(df_res)
result = pd.concat(result_df).groupby(['HIERARCHY 1', 'HIERARCHY 2', 'HIERARCHY 3','ITEM NUMBER', 'date']).mean()
You can then group and aggregate your concatenated result by ['HIERARCHY 1', 'HIERARCHY 2', 'HIERARCHY 3','ITEM NUMBER', 'date'], filter NaN values and calculate absolute error:
result = result[~result['ACTUAL'].isna()]
forecast_avail_filter = result[result.columns[1:]].dropna(how='all').index
result = result.loc[forecast_avail_filter]
for col in result.columns[1:]:
ref = col.strip('FORECAST ')
result['ABS ERR ' ref] = (result["ACTUAL"] - result[col]).abs()
print(result)
Output:
ACTUAL FORECAST T-1 FORECAST T-3 ABS ERR -1 ABS ERR -3
HIERARCHY 1 HIERARCHY 2 HIERARCHY 3 ITEM NUMBER date
Level 1 Group A Category 1 Item 1 2020-07-01 112.0 106.0 NaN 6.0 NaN
2020-08-01 114.0 59.0 NaN 55.0 NaN
2020-09-01 76.0 109.0 99.0 33.0 23.0
2020-10-01 107.0 118.0 73.0 11.0 34.0
2020-11-01 60.0 43.0 35.0 17.0 25.0
2020-12-01 31.0 101.0 24.0 70.0 7.0
2021-01-01 82.0 65.0 50.0 17.0 32.0
2021-02-01 54.0 71.0 111.0 17.0 57.0
2021-03-01 44.0 119.0 97.0 75.0 53.0
2021-04-01 25.0 47.0 64.0 22.0 39.0
2021-05-01 69.0 102.0 91.0 33.0 22.0
2021-06-01 53.0 89.0 100.0 36.0 47.0
2021-07-01 110.0 NaN 34.0 NaN 76.0
2021-08-01 56.0 81.0 87.0 25.0 31.0
2021-09-01 86.0 28.0 NaN 58.0 NaN
2021-10-01 61.0 23.0 79.0 38.0 18.0
Group B Category 1 Item 2 2020-07-01 96.0 99.0 NaN 3.0 NaN
2020-08-01 35.0 24.0 NaN 11.0 NaN
2020-09-01 109.0 106.0 56.0 3.0 53.0
2020-10-01 83.0 104.0 28.0 21.0 55.0
2020-11-01 66.0 45.0 60.0 21.0 6.0
2020-12-01 55.0 89.0 47.0 34.0 8.0
2021-01-01 42.0 93.0 52.0 51.0 10.0
2021-02-01 114.0 21.0 33.0 93.0 81.0
2021-03-01 46.0 80.0 73.0 34.0 27.0
2021-04-01 107.0 37.0 20.0 70.0 87.0
2021-05-01 116.0 76.0 118.0 40.0 2.0
2021-06-01 25.0 65.0 22.0 40.0 3.0
2021-07-01 77.0 NaN 97.0 NaN 20.0
2021-08-01 27.0 57.0 90.0 30.0 63.0
2021-09-01 101.0 115.0 NaN 14.0 NaN
2021-10-01 75.0 43.0 48.0 32.0 27.0
Level 2 Group F Category 1 Item 2 2020-07-01 107.0 62.0 NaN 45.0 NaN
2020-08-01 60.0 27.0 NaN 33.0 NaN
2020-09-01 89.0 22.0 81.0 67.0 8.0
2020-10-01 48.0 25.0 118.0 23.0 70.0
2020-11-01 109.0 87.0 24.0 22.0 85.0
2020-12-01 44.0 21.0 86.0 23.0 42.0
2021-01-01 96.0 30.0 75.0 66.0 21.0
2021-02-01 26.0 65.0 56.0 39.0 30.0
2021-03-01 41.0 93.0 105.0 52.0 64.0
2021-04-01 32.0 53.0 88.0 21.0 56.0
2021-05-01 28.0 38.0 46.0 10.0 18.0
2021-06-01 78.0 67.0 116.0 11.0 38.0
2021-07-01 99.0 NaN 50.0 NaN 49.0
2021-08-01 71.0 114.0 59.0 43.0 12.0
2021-09-01 61.0 82.0 NaN 21.0 NaN
2021-10-01 40.0 36.0 90.0 4.0 50.0