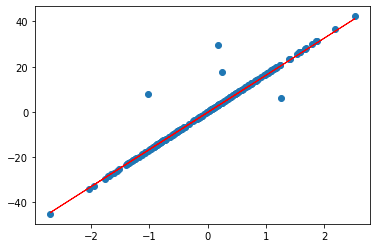
I am trying to play around to see how outliers in a dataset might affect a Linear Regression model. The issue I'm having is I don't exactly know how to add outliers to a dataset, I've only found loads of articles online about how to detect and remove them.
This is the code I have so far:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.linear_model import LinearRegression
from sklearn.datasets import make_regression
# Generate regression dataset
X, y = make_regression(
n_samples=1000,
n_features=1,
noise=0.0,
bias=0.0,
random_state=42,
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
regressor = LinearRegression()
regressor.fit(X_train, y_train) # Training the algorithm
y_pred = regressor.predict(X_test)
print("R2 Score:", metrics.r2_score(y_test, y_pred))
print("Mean Absolute Error:", metrics.mean_absolute_error(y_test, y_pred))
print("Mean Squared Error:", metrics.mean_squared_error(y_test, y_pred))
print("Root Mean Squared Error:", np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
plt.scatter(X_test, y_test)
plt.plot(X_test, y_pred, color="red", linewidth=1)
plt.show()
And this is the output:
My question is how can I add outliers to this clean dataset in order to see the effects outliers will have on the resulting model?
Any help would be appreciated, thanks!
CodePudding user response:
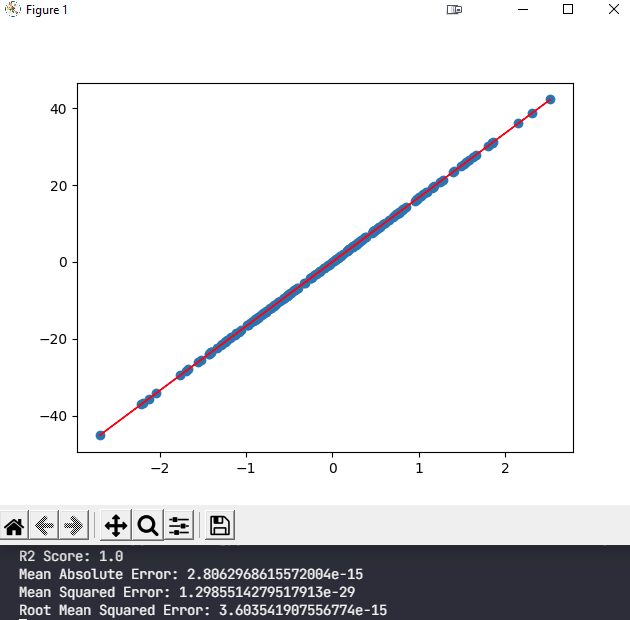
You can add values directly to X and y. Since the slope is significant enough, this will end up giving you outliers. You could us any method you want really.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.linear_model import LinearRegression
from sklearn.datasets import make_regression
# Generate regression dataset
X, y = make_regression(
n_samples=1000,
n_features=1,
noise=0.0,
bias=0.0,
random_state=42,
)
for x in range(20):
X=np.append(X, np.random.choice(X.flatten()))
y=np.append(y, np.random.choice(y.flatten()))
X = X.reshape(-1,1)
y = y.reshape(-1,1)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
regressor = LinearRegression()
regressor.fit(X_train, y_train) # Training the algorithm
y_pred = regressor.predict(X_test)
print("R2 Score:", metrics.r2_score(y_test, y_pred))
print("Mean Absolute Error:", metrics.mean_absolute_error(y_test, y_pred))
print("Mean Squared Error:", metrics.mean_squared_error(y_test, y_pred))
print("Root Mean Squared Error:", np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
plt.scatter(X_test, y_test)
plt.plot(X_test, y_pred, color="red", linewidth=1)
plt.show()