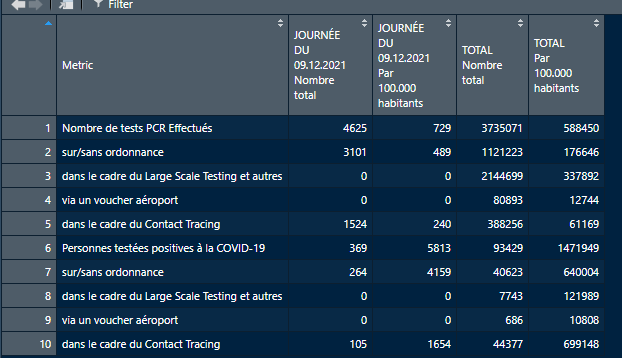
I am new in web scraping with r and I am trying to get a daily updated object which is probably not text. The url is
Alternate:
If you simply want to pull items then process you could extract each column as an item in a list. Replace br elements such that the content within those end up in a comma separated list:
library(rvest)
library(magrittr)
library(stringi)
library(xml2)
page <- read_html("https://covid19.public.lu/en.html")
xml_find_all(page, ".//br") %>% xml_add_sibling("span", ",") #This method from https://stackoverflow.com/a/46755666 @hrbrmstr
xml_find_all(page, ".//br") %>% xml_remove()
columns <- page %>% html_elements(".cmp-gridStat__item")
map(columns, ~ .x %>%
html_elements("p") %>%
html_text(trim = T) %>%
gsub("\n\\s{2,}", " ", .)
%>%
stri_remove_empty())