I have an .xlsx file with several dataframes with common index in one sheet. An example:
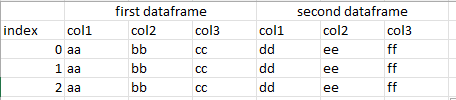
What is a good way to load it and have two separate dataframes, one being first dataframe and second being second dataframe both with the same index as in the .xlsx file?
The results are:
df1 = pd.DataFrame(data={'col1': [aa, aa, aa], 'col2': [bb, bb, bb], 'col3': [cc, cc, cc]}, index=[0,1,2])
df2 = pd.DataFrame(data={'col1': [dd, dd, dd], 'col2': [ee, ee, ee], 'col3': [ff, ff, ff]},index=[0,1,2])
CodePudding user response:
try something like this
import pandas as pd
df0 = pd.read_excel('mybook.xlsx', header=[0,1])
df0.head()
outputs:
Unnamed: 0_level_0 firstdataframe seconddataframe
index col1 col2 col3 col1 col2 col3
0 0 aa bb cc dd ee ff
1 1 aa bb cc dd ee ff
2 2 aa bb cc dd ee ff
so, multindex might help (header=[0,1] means first and second row is used as col index)
then,
df1=df0.loc[:,'firstdataframe']
df1
outputs
col1 col2 col3
0 aa bb cc
1 aa bb cc
2 aa bb cc
and then,
df2=df0.loc[:,'seconddataframe']
df2
ouputs
col1 col2 col3
0 dd ee ff
1 dd ee ff
2 dd ee ff
read https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html
CodePudding user response:
Use the usecols parameter from read_excel
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html