The identical dataset of funding dates vs disciplines plotted differently using plotly.express (px) lines and plotly.graph_objects (go) scatter traces. The shape of the plots look identical, but dates are wrong in the go traces. Any suggestions on what may be wrong here? Thank you.
Using px.line:
fig = px.line(df_fig, x='date_list', y='monthly_avg', color='main_discipline')
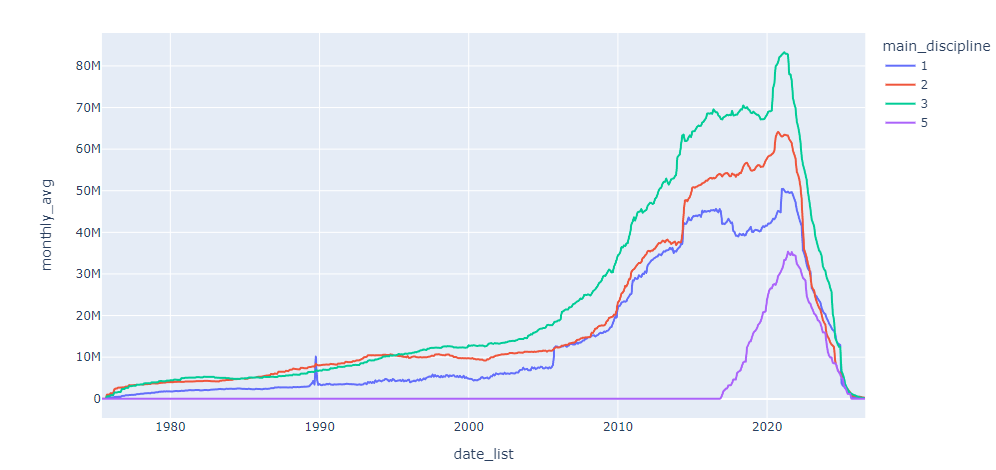
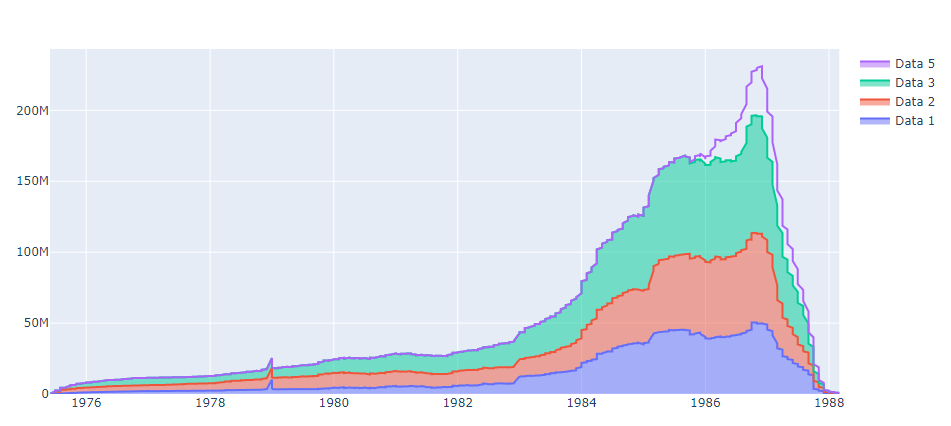
Using go.Figure
plot = go.Figure()
plot.add_trace(go.Scatter(
name = 'Data 1',
x = df_fig.date_list,
y = df_fig[df_fig.main_discipline==1].monthly_avg,
stackgroup='one'
))
plot.add_trace(go.Scatter(
name = 'Data 2',
x = df_fig.date_list,
y = df_fig[df_fig.main_discipline==2].monthly_avg,
stackgroup='one'
))
plot.add_trace(go.Scatter(
name = 'Data 3',
x = df_fig.date_list,
y = df_fig[df_fig.main_discipline==3].monthly_avg,
stackgroup='one'
))
plot.add_trace(go.Scatter(
name = 'Data 5',
x = df_fig.date_list,
y = df_fig[df_fig.main_discipline==5].monthly_avg,
stackgroup='one'
))
The date_list is of type datetime64:
df_fig.date_list
0 1975-06-01
1 1975-06-01
2 1975-06-01
3 1975-06-01
4 1975-07-01
...
2455 2026-07-01
2456 2026-08-01
2457 2026-08-01
2458 2026-08-01
2459 2026-08-01
Name: date_list, Length: 2460, dtype: datetime64[ns]
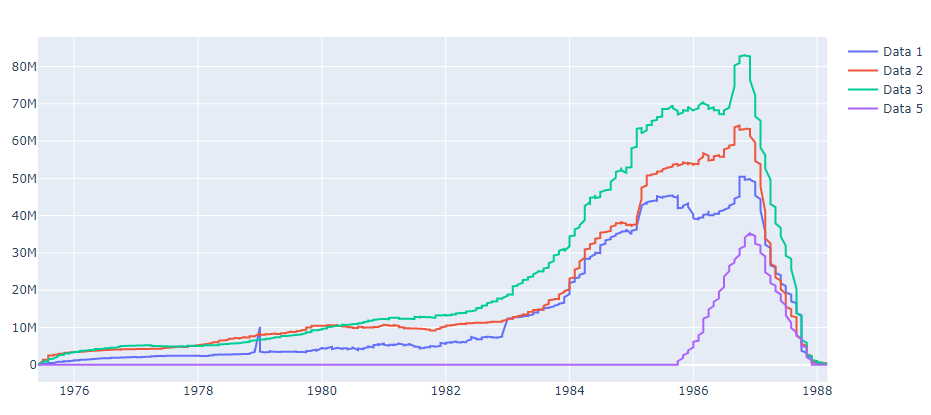
Removing stackgroup produced plots of the same shape, but the wrong ending date persists at Mar 1988 instead of Jul 2026.
Here is the data frame with the first 20 rows, the date issuse persist
df_fig[['date_list', 'main_discipline', 'monthly_avg']]
date_list main_discipline monthly_avg
0 1975-06-01 1 0.000000
1 1975-06-01 2 15494.000000
2 1975-06-01 3 0.000000
3 1975-06-01 5 0.000000
4 1975-07-01 1 0.000000
5 1975-07-01 2 16827.333333
6 1975-07-01 3 0.000000
7 1975-07-01 5 0.000000
8 1975-08-01 1 3880.252381
9 1975-08-01 2 16827.333333
10 1975-08-01 3 0.000000
11 1975-08-01 5 0.000000
12 1975-09-01 1 3880.252381
13 1975-09-01 2 16827.333333
14 1975-09-01 3 0.000000
15 1975-09-01 5 0.000000
16 1975-10-01 1 201134.985609
17 1975-10-01 2 986805.179029
18 1975-10-01 3 590159.728836
19 1975-10-01 5 0.000000
Using px.line
fig = px.line(df_fig[df_fig.main_discipline==1], x='date_list', y='monthly_avg')
fig.show()
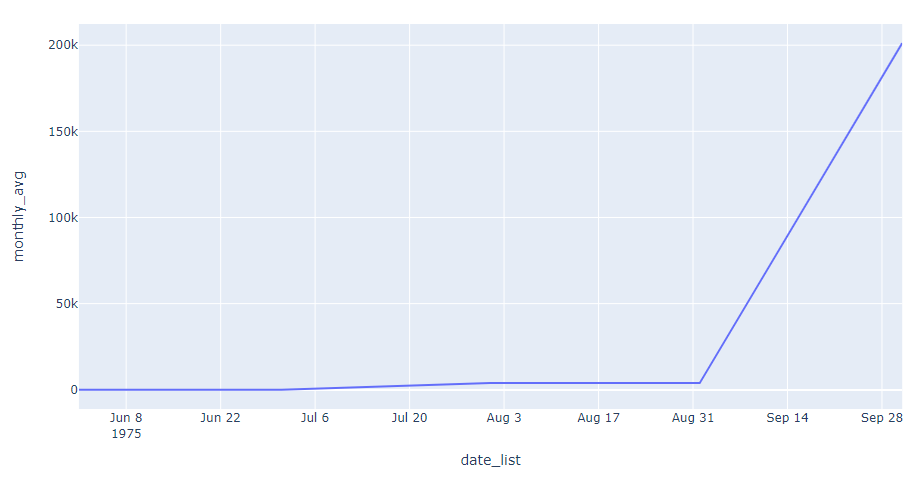
Using go.Scatter
plot = go.Figure()
plot.add_trace(go.Scatter(
name = 'Data 1',
x = df_fig.date_list,
y = df_fig[df_fig.main_discipline==1].monthly_avg,
))
plot.show()
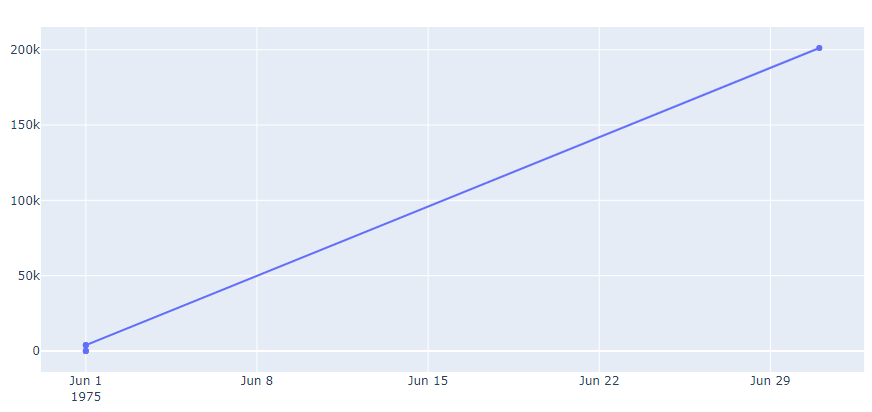
CodePudding user response:
This is happening because you are unintentionally passing different data to go.Scatter and px.line. In the below code snippet, you are passing x=df_fig.date_list which is all of the date_list values, but only some of the monthly_avg (subset by main_discipline==1).
plot = go.Figure()
plot.add_trace(go.Scatter(
name = 'Data 1',
x = df_fig.date_list,
y = df_fig[df_fig.main_discipline==1].monthly_avg,
))
plot.show()
Plotly should probably throw ValueError: all arguments should have the same length for this situation, but instead tries to plot it anyway by shortening the array you passed to x to match the array you passed to y. df_fig[df_fig.main_discipline==1].monthly_avg has a length of 5, and the first 5 values of df_fig.date_list are the following:
>>> df_fig.date_list
0 1975-06-01
1 1975-06-01
2 1975-06-01
3 1975-06-01
4 1975-07-01
This explains the plot you were getting, but this is definitely not what you want and instead this should give you the correct result:
plot = go.Figure()
plot.add_trace(go.Scatter(
name = 'Data 1',
x = df_fig[df_fig.main_discipline==1].date_list,
y = df_fig[df_fig.main_discipline==1].monthly_avg,
))
plot.show()
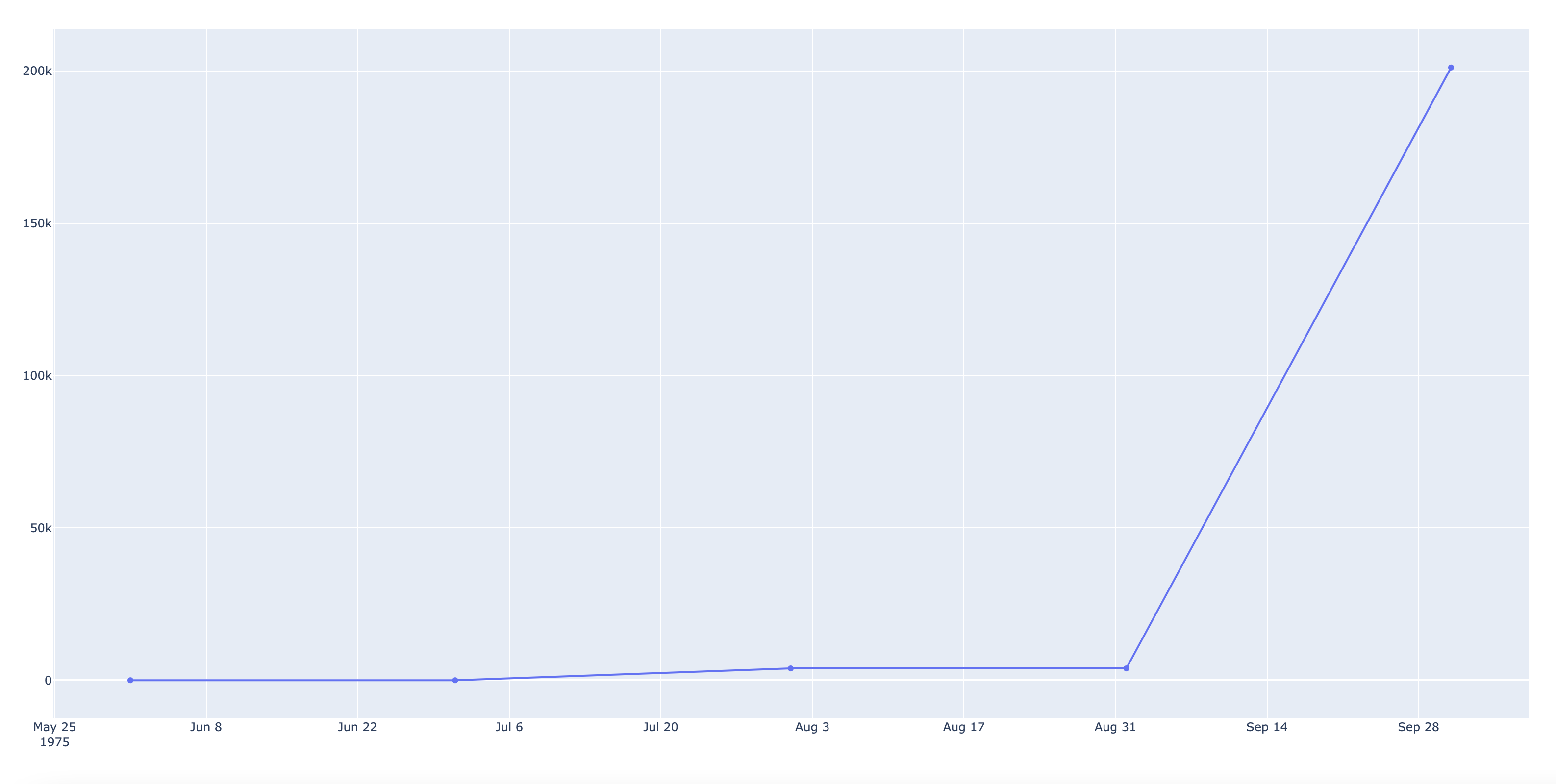
CodePudding user response:
- you have just shared a list of dates, have created a dataframe that has all required columns
- refactor use of go to be less repetitive
- fundamentally you are requesting different formatting by setting
stackgroup - px will use scattergl for very large plots, this doesn't support
stackgroup. Hence updating traces does not work to make px plot similar to go plot for large date range
import numpy as np
import plotly.graph_objects as go
import plotly.express as px
import pandas as pd
ed = "1-aug-2026"
ed = "1-aug-1976"
df_fig = pd.DataFrame({"date_list": pd.date_range("1-jun-1975", ed)}).assign(
main_discipline=lambda d: ((d.index % 5) 1).astype(str),
monthly_avg=lambda d: np.geomspace(1, 5 * 10 ** 7, len(d)) * d["main_discipline"].astype(int),
)
fig = px.line(df_fig, x='date_list', y='monthly_avg', color='main_discipline')
fig.show()
try:
fig.for_each_trace(lambda t: t.update(stackgroup="one"))
except ValueError:
print(f"{fig.data[0].type} doesn't support stackgroup")
fig.show()
plot = go.Figure()
for k, d in df_fig.groupby("main_discipline"):
plot.add_trace(go.Scatter(name="Data " k, x=d["date_list"], y=d["monthly_avg"], stackgroup="one"))
plot.show()
plot.update_traces(stackgroup=None).show()