I have a column where each row contains a list of strings of varying lengths. I need to create a new column that has a list of booleans (equivalent to the original list) of whether or not each element is found in ANOTHER (larger) list.
This is what I am doing and well, it clearly does not work. I based it off of this question:
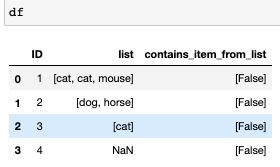
desired output:
ID list contains_item_from_list
1 [cat,cat,mouse] [True, True, True]
2 [dog,horse] [True, False]
3 [cat] [True]
4 NaN [False]
CodePudding user response:
explode flattens all the lists in a Series, but items that were in the same list all share the same index that the list they came from did, so after you use isin to check which items of main_list are in the Series, you can use groupby with level=0 to group by the 0th (first) level of the index, and then convert them back to lists:
df['contains_item_from_list'] = df['list'].explode().isin(main_list).groupby(level=0).apply(list)
Output:
>>> df
0 [True, True, True]
1 [True, False]
2 [True]
3 [False]
Name: list, dtype: object
CodePudding user response:
You can do explode then isin
df['new'] = df['list'].explode().isin(main_list).groupby(level=0).any()
df
Out[130]:
ID list new
0 1 [cat, cat, mouse] True
1 2 [dog, horse] True
2 3 [cat] True
3 4 NaN False
Update
df['new'] = df['list'].explode().isin(main_list).groupby(level=0).agg(list)
df
Out[132]:
ID list new
0 1 [cat, cat, mouse] [True, True, True]
1 2 [dog, horse] [True, False]
2 3 [cat] [True]
3 4 NaN [False]
CodePudding user response:
You can also apply a function that iterates over each list in list. This should be faster than exploding the column:
main_set = set(main_list)
df["contains_item_from_list"] = df['list'].apply(lambda x: [w in main_set for w in x] if isinstance(x, list) else [x in main_set])
Output:
ID list contains_item_from_list
0 1 [cat, cat, mouse] [True, True, True]
1 2 [dog, horse] [True, False]
2 3 [cat] [True]
3 4 NaN [False]
CodePudding user response:
Use list comprehension, easy and faster
df["contains_item_from_list"]= df['list'].fillna('xx').apply(lambda x: [val in main_list for val in x])
ID list contains_item_from_list
0 1 [cat, cat, mouse] [True, True, True]
1 2 [dog, horse] [True, False]
2 3 [cat] [True]
3 4 NaN [False]