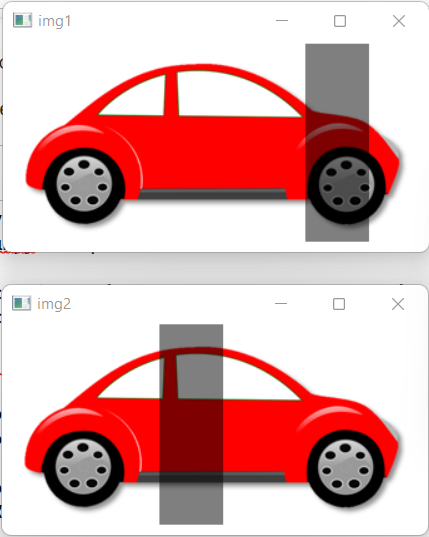
I have these images and there is a shadow in all images. I target is making a single image of a car without shadow by using these three images:
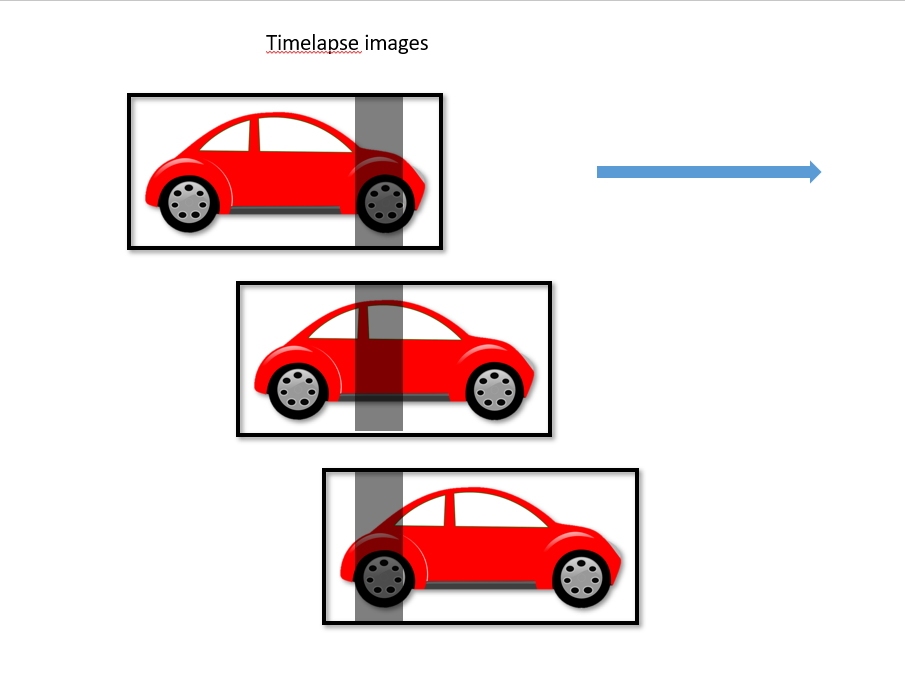
Finally, how can I get this kind of image as shown below:
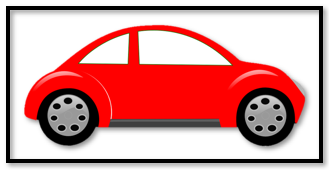
Any kind of help or suggestions are appreciated.
CodePudding user response:
Here's a possible solution. The overall idea is to compute the location of the shadows, produce a binary mask identifying the location of the shadows and use this information to copy pixels from all the cropped sub-images.
Let's see the code. The first problem is to locate the three images. I used the black box to segment and crop each car, like this:
# Imports:
import cv2
import numpy as np
# image path
path = "D://opencvImages//"
fileName = "qRLI7.png"
# Reading an image in default mode:
inputImage = cv2.imread(path fileName)
# Get the HSV image:
hsvImage = cv2.cvtColor(inputImage, cv2.COLOR_BGR2HSV)
# Get the grayscale image:
grayImage = cv2.cvtColor(inputImage, cv2.COLOR_BGR2GRAY)
showImage("grayImage", grayImage)
# Threshold via Otsu:
_, binaryImage = cv2.threshold(grayImage, 5, 255, cv2.THRESH_BINARY_INV)
cv2.imshow("binaryImage", binaryImage)
cv2.waitKey(0)
The previous bit uses the grayscale version of the image and applies a fixed binarization using a threshold of 5. I also pre-compute the HSV version of the original image. The result of the thresholding is this:
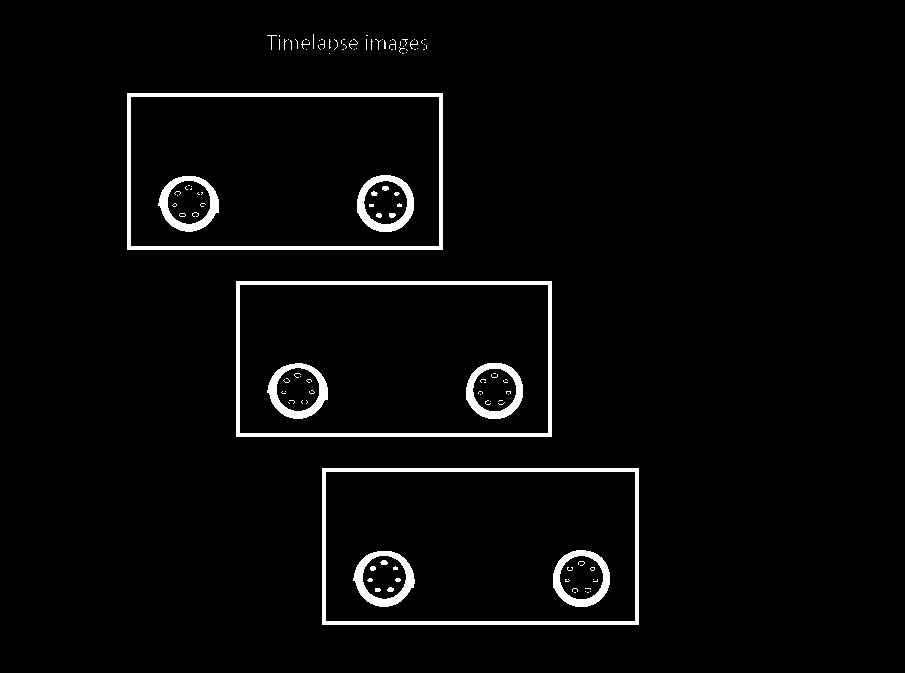
I'm trying to get the black rectangles and use them to crop each car. Let's get the contours and filter them by area, as the black rectangles on the binary image have the biggest area:
for i, c in enumerate(currentContour):
# Get the contour's bounding rectangle:
boundRect = cv2.boundingRect(c)
# Get the dimensions of the bounding rect:
rectX = boundRect[0]
rectY = boundRect[1]
rectWidth = boundRect[2]
rectHeight = boundRect[3]
# Get the area:
blobArea = rectWidth * rectHeight
minArea = 20000
if blobArea > minArea:
# Deep local copies:
hsvImage = hsvImage.copy()
localImage = inputImage.copy()
# Get the S channel from the HSV image:
(H, S, V) = cv2.split(hsvImage)
# Crop image:
croppedImage = V[rectY:rectY rectHeight, rectX:rectX rectWidth]
localImage = localImage[rectY:rectY rectHeight, rectX:rectX rectWidth]
_, binaryMask = cv2.threshold(croppedImage, 0, 255, cv2.THRESH_OTSU cv2.THRESH_BINARY_INV)
After filtering each contour to get the biggest one, I need to locate the position of the shadow. The shadow is mostly visible in the HSV color space, particularly, in the V channel. I cropped two versions of the image: The original BGR image, now cropped, and the V cropped channel of the HSV image. This is the binary mask that results from applying an automatic thresholding on the S channel :
To locate the shadow I only need the starting x coordinate and its width, because the shadow is uniform across every cropped image. Its height is equal to each cropped image's height. I reduced the V image to a row, using the SUM mode. This will sum each pixel across all columns. The biggest values will correspond to the position of the shadow:
# Image reduction:
reducedImg = cv2.reduce(binaryMask, 0, cv2.REDUCE_SUM, dtype=cv2.CV_32S)
# Normalize image:
max = np.max(reducedImg)
reducedImg = reducedImg / max
# Clip the values to [0,255]
reducedImg = np.clip((255 * reducedImg), 0, 255)
# Convert the mat type from float to uint8:
reducedImg = reducedImg.astype("uint8")
_, shadowMask = cv2.threshold(reducedImg, 250, 255, cv2.THRESH_BINARY)
The reduced image is just a row:

The white pixels denote the largest values. The location of the shadow is drawn like a horizontal line with the largest area, that is, the most contiguous white pixels. I process this row by getting contours and filtering, again, to the largest area:
# Get the biggest rectangle:
subContour, _ = cv2.findContours(shadowMask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for j, s in enumerate(subContour):
# Get the contour's bounding rectangle:
boundRect = cv2.boundingRect(s)
# Get the dimensions of the bounding rect:
rectX = boundRect[0]
rectY = boundRect[1]
rectWidth = boundRect[2]
rectHeight = boundRect[3]
# Get the area:
blobArea = rectWidth * rectHeight
minArea = 30
if blobArea > minArea:
# Get image dimensions:
(imageHeight, imageWidth) = localImage.shape[:2]
# Set an empty array, this will be the binary mask
shadowMask = np.zeros((imageHeight, imageWidth, 3), np.uint8)
color = (255, 255, 255)
cv2.rectangle(shadowMask, (int(rectX), int(0)),
(int(rectX rectWidth), int(0 imageHeight)), color, -1)
# Invert mask:
shadowMask = 255 - shadowMask
# Store mask and cropped image:
shadowRois.append((shadowMask.copy(), localImage.copy()))
Alright, with that information I create a mask, where the only thing drawn in white is the location of the mask. I store this mask and the original BGR crop in the shadowRois list.
What follows is a possible method to use this information and create a full image. The idea is that I use the information of each mask to copy all the non-masked pixels. I accumulate this information on a buffer, initially an empty image, like this:
# Prepare image buffer:
buffer = np.zeros((100, 100, 3), np.uint8)
# Loop through cropped images and produce the final image:
for r in range(len(shadowRois)):
# Get data from the list:
(mask, img) = shadowRois[r]
# Get image dimensions:
(imageHeight, imageWidth) = img.shape[:2]
# Resize the buffer:
newSize = (imageWidth, imageHeight)
buffer = cv2.resize(buffer, newSize, interpolation=cv2.INTER_AREA)
# Get the image mask:
temp = cv2.bitwise_and(img, mask)
# Set info in buffer, substitute the black pixels
# for the new data:
buffer = np.where(temp == (0, 0, 0), buffer, temp)
cv2.imshow("Composite Image", buffer)
cv2.waitKey(0)
The result is this:

CodePudding user response:
According to @fmw42's suggestions in comments, I achieved to the target and below I am posting it:
import cv2
import numpy as np
img_1 = cv2.imread('1.png', cv2.COLOR_BGR2RGB)
img_2 = cv2.imread('2.png', cv2.COLOR_BGR2RGB)
img = np.maximum(img_1, img_2)
cv2.imshow('img1', img_1)
cv2.imshow('img2', img_2)
cv2.imshow('img', img)
cv2.waitKey(0)
Input images are:
and when you run the code you will get following result:
