I am scraping a json api using scrapy and want to loop through the offers and then the outcomes as shown in the screenshot below. I am getting to the offers OK but then not sure what to write for the get() as its unlabeled. Everything I have tried leads to an error of 'list' object has no attribute get.
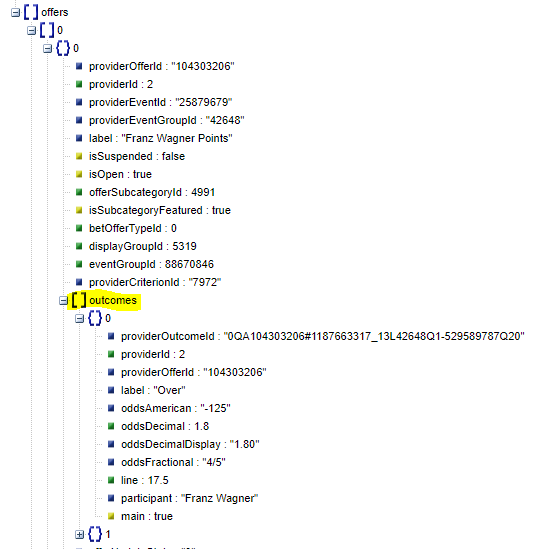
My code is below:
import scrapy
import json
class DkSpider(scrapy.Spider):
name = 'dk'
allowed_domains = ['sportsbook.draftkings.com']
start_urls = ['https://sportsbook.draftkings.com//sites/US-SB/api/v4/eventgroups/88670846/categories/583/subcategories/4991']
def parse(self, response):
items = json.loads(response.body)
cats = items.get('eventGroup').get('offerCategories')
for cat in cats:
groups = str(cat.get('name'))
if groups == "Player Props":
subcats = cat.get('offerSubcategoryDescriptors')
for subcat in subcats:
markets = str(subcat.get('name'))
if markets == "Points":
games = subcat.get('offerSubcategory').get('offers')
for game in games:
outcomes = game.get('outcomes')
CodePudding user response:
If there was only one blank entry than you need to write for game in games[0]:, but since you have multiple blank keys then you need to loop through them to get all the info you want.
Solution with your approach:
import scrapy
class DkSpider(scrapy.Spider):
name = 'dk'
allowed_domains = ['sportsbook.draftkings.com']
start_urls = ['https://sportsbook.draftkings.com//sites/US-SB/api/v4/eventgroups/88670846/categories/583/subcategories/4991']
def parse(self, response):
items = response.json()
cats = items.get('eventGroup').get('offerCategories')
for cat in cats:
groups = str(cat.get('name'))
if groups == "Player Props":
subcats = cat.get('offerSubcategoryDescriptors')
for subcat in subcats:
markets = str(subcat.get('name'))
if markets == "Points":
games = subcat.get('offerSubcategory').get('offers')
for game in games:
for in_game in game:
outcomes = in_game.get('outcomes')
for outcome in outcomes:
print(outcome['participant'])
But notice that you're doing more iterations than you actually need so the runtime will be longer. Either put a break or just do something like this:
import scrapy
import json
class DkSpider(scrapy.Spider):
name = 'dk'
allowed_domains = ['sportsbook.draftkings.com']
start_urls = ['https://sportsbook.draftkings.com//sites/US-SB/api/v4/eventgroups/88670846/categories/583/subcategories/4991']
def parse(self, response):
# from scrapy.shell import inspect_response
# inspect_response(response, self)
games = json.loads(response.body)['eventGroup']['offerCategories'][1]['offerSubcategoryDescriptors'][1]['offerSubcategory']['offers']
for game in games:
for in_game in game:
outcomes = in_game.get('outcomes')
for outcome in outcomes:
# Get whatever info you want here
print(outcome['participant'])