I have two data frame df1 and df2.
df1 have 174 columns and df2 have 175 columns.
How I can find which column is extra ?
CodePudding user response:
Just convert column lists into sets, and use diff operations on these sets, like this:
df2.columns.toSet.diff(df1.columns.toSet)
Please note that the order of comparison matters, like, df1.columns.toSet.diff(df2.columns.toSet) won't produce a required diff. If you want to have diff independent of position, you can use something like this: df2.columns.toSet.diff(df1.columns.toSet).union(df1.columns.toSet.diff(df2.columns.toSet))
CodePudding user response:
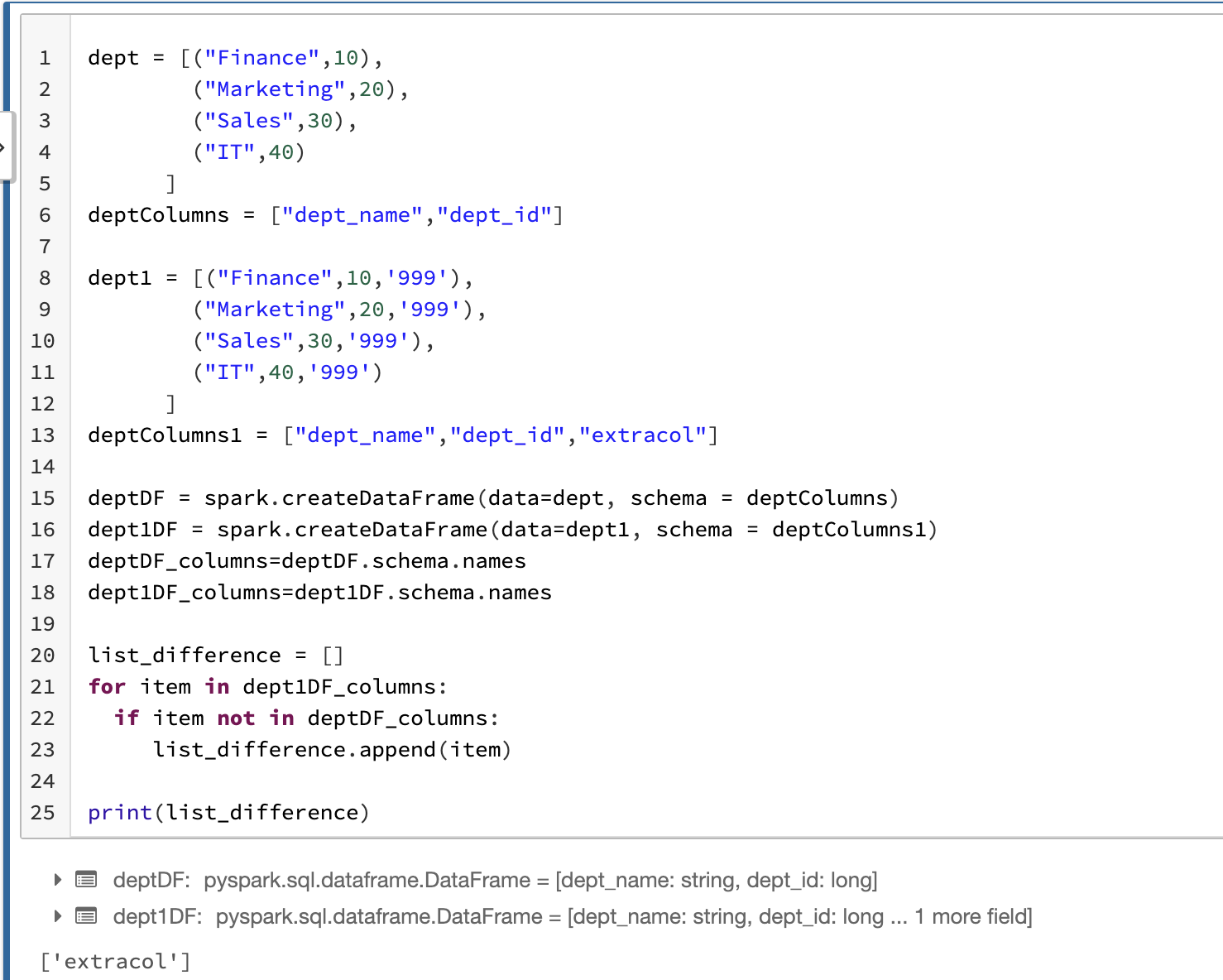
In pyspark , You can use below logic .
dept = [("Finance",10),
("Marketing",20),
("Sales",30),
("IT",40)
]
deptColumns = ["dept_name","dept_id"]
dept1 = [("Finance",10,'999'),
("Marketing",20,'999'),
("Sales",30,'999'),
("IT",40,'999')
]
deptColumns1 = ["dept_name","dept_id","extracol"]
deptDF = spark.createDataFrame(data=dept, schema = deptColumns)
dept1DF = spark.createDataFrame(data=dept1, schema = deptColumns1)
deptDF_columns=deptDF.schema.names
dept1DF_columns=dept1DF.schema.names
list_difference = []
for item in dept1DF_columns:
if item not in deptDF_columns:
list_difference.append(item)
print(list_difference)
Tested code :