How do I arrange the columns of a pandas pivot table?
For example for the pivot output, how can I have D and E swap positions and how can I swap the large and small positions?
EDIT: I am looking for a solution which allows for a custom order that would work for other instances
#Sample Dataframe
df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo",
"bar", "bar", "bar", "bar"],
"B": ["one", "one", "one", "two", "two",
"one", "one", "two", "two"],
"C": ["small", "large", "large", "small",
"small", "large", "small", "small",
"large"],
"D": [1, 2, 2, 3, 3, 4, 5, 6, 7],
"E": [2, 4, 5, 5, 6, 6, 8, 9, 9]})
#Dataframe:
A B C D E
0 foo one small 1 2
1 foo one large 2 4
2 foo one large 2 5
3 foo two small 3 5
4 foo two small 3 6
5 bar one large 4 6
6 bar one small 5 8
7 bar two small 6 9
8 bar two large 7 9
#Code used to pivot
display(pd.pivot_table(df,index=['A','B'],columns=['C'],values=['D','E'],aggfunc=np.sum))
Pivot table output:
D E
C large small large small
A B
bar one 4.0 5.0 6.0 8.0
two 7.0 6.0 9.0 9.0
foo one 4.0 1.0 9.0 2.0
two NaN 6.0 NaN 11.0
CodePudding user response:
You can define yourself the codes attribute of a MultiIndex instance (like an ordered CategoricalIndex)
out.columns = out.columns.set_codes([
out.columns.get_level_values(0).map({'E': 0, 'D': 1}),
out.columns.get_level_values(1).map({'small': 0, 'large': 1})
])
print(out)
# Output
D E
C small large small large
A B
bar one 4.0 5.0 6.0 8.0
two 7.0 6.0 9.0 9.0
foo one 4.0 1.0 9.0 2.0
two NaN 6.0 NaN 11.0
You can define a custom mapping for month like this:
import calendar
month_codes = dict(enumerate(calendar.month_abbr[1:]))
print(month_codes)
# Output
{0: 'Jan', 1: 'Feb', 2: 'Mar', 3: 'Apr', 4: 'May', 5: 'Jun',
6: 'Jul', 7: 'Aug', 8: 'Sep', 9: 'Oct', 10: 'Nov', 11: 'Dec'}
CodePudding user response:
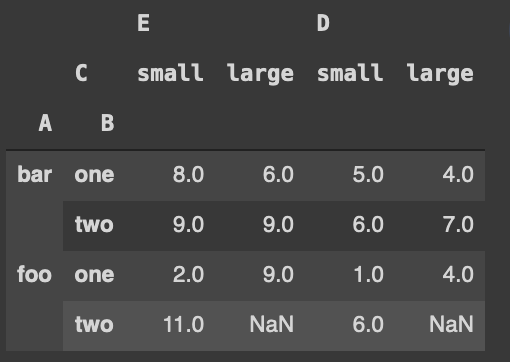
Is this what you are looking to do?
pivot1 = pd.pivot_table(df,index=['A','B'],columns=['C'], values=['D','E'],aggfunc=np.sum)
pivot2 = pivot1[[('E', 'small'),
('E', 'large'),
('D', 'small'),
('D', 'large')]]
CodePudding user response:
You can use sort_index with ascending=False in this example:
df.sort_index(1, ascending=False)
Output
E D
C small large small large
A B
bar one 8.0 6.0 5.0 4.0
two 9.0 9.0 6.0 7.0
foo one 2.0 9.0 1.0 4.0
two 11.0 NaN 6.0 NaN