Similar to this previous 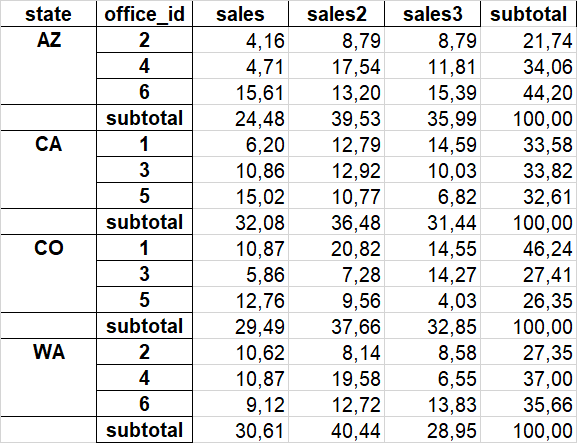
Update
It would be ideal to groupby both state and office id for situations where there are repeating values for office id column. Here is an example:
df = pd.DataFrame({'state': ['CA', 'WA', 'CO', 'AZ'] * 3,
'office_id': [1,1,1,2,2,2] * 2,
'sales': [np.random.randint(100000, 999999) for _ in range(12)],
'sales2': [np.random.randint(100000, 999999) for _ in range(12)],
'sales3': [np.random.randint(100000, 999999) for _ in range(12)]})
This should then yield:
CodePudding user response:
We need create you need step by step, include groupby with append the subtotal per group on column , then transform the total sum with state
s = df.groupby('state')[['sales','sales2','sales3']].sum().assign(office_id = 'Subtotal').set_index('office_id',append=True)
out = pd.concat([df,s.reset_index()]).sort_values('state')
out['Subtotal'] = out[['sales','sales2','sales3']].sum(axis=1)
v = out.groupby('state')['Subtotal'].transform('sum')/2
out.update(out[['sales','sales2','sales3','Subtotal']].div(v,axis=0))
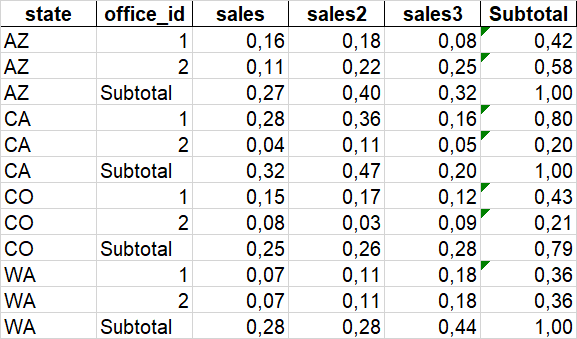
out
state office_id sales sales2 sales3 Subtotal
3 AZ 4 0.047124 0.175385 0.118068 0.340578
7 AZ 2 0.041571 0.087926 0.087902 0.217399
11 AZ 6 0.156107 0.131998 0.153919 0.442023
0 AZ Subtotal 0.244802 0.395309 0.359889 1.000000
0 CA 1 0.062026 0.127860 0.145870 0.335756
4 CA 5 0.150188 0.107702 0.068203 0.326092
8 CA 3 0.108636 0.129193 0.100323 0.338152
1 CA Subtotal 0.320849 0.364755 0.314396 1.000000
2 CO 3 0.058604 0.072756 0.142734 0.274095
6 CO 1 0.108667 0.208210 0.145513 0.462390
10 CO 5 0.127604 0.095630 0.040282 0.263516
2 CO Subtotal 0.294875 0.376596 0.328529 1.000000
1 WA 2 0.106233 0.081434 0.085797 0.273463
5 WA 6 0.091156 0.127159 0.138270 0.356585
9 WA 4 0.108694 0.195807 0.065451 0.369952
3 WA Subtotal 0.306083 0.404399 0.289518 1.000000
CodePudding user response:
Here's a one-liner (except for the extra cols variable to shorten the code overall):
cols = df.filter(like='sales').columns
new_df = df.assign(**{k:list(v.values()) for k,v in df[cols].apply(lambda c:c/c.groupby(df['state']).transform(sum)).to_dict().items()}).groupby('state').apply(lambda x:x.append(pd.Series({'office_id':'subtotal',**x.sum().to_dict()},name=''))).droplevel(1).drop('state',axis=1).reset_index()
Output:
>>> new_df
state office_id sales sales2 sales3
0 AZ 4 0.192500 0.443666 0.328069
1 AZ 2 0.169814 0.222423 0.244248
2 AZ 6 0.637686 0.333910 0.427683
3 AZ subtotal 0.964236 0.636485 1.399280
4 CA 1 0.193319 0.350536 0.463970
5 CA 5 0.468094 0.295272 0.216932
6 CA 3 0.338587 0.354192 0.319098
7 CA subtotal 1.007825 0.980298 1.011877
8 CO 3 0.198743 0.193194 0.434464
9 CO 1 0.368519 0.552873 0.442923
10 CO 5 0.432739 0.253933 0.122613
11 CO subtotal 0.826401 1.364314 0.809285
12 WA 2 0.347072 0.201369 0.296343
13 WA 6 0.297815 0.314438 0.477587
14 WA 4 0.355113 0.484192 0.226070
15 WA subtotal 0.844785 1.089840 1.065375
It's gnarly, so I'll provide a breakdown:
new_df = (df
# This assign call selects all the sales columns, computes the percentages, and assigns them back to the dataframe
.assign(**{
k: list(v.values())
for k,v
in df[cols].apply(
lambda c: c / c.groupby(df['state']).transform(sum)
)
.to_dict()
.items()
})
.groupby('state')
.apply(lambda x: x.append(
pd.Series(
{
'office_id': 'subtotal',
**(x[cols]
.sum(1)
.to_dict()
)
},
name=''
)
))
.droplevel(1)
.drop('state', axis=1)
.reset_index()
)