I'm trying to make a regex that matches strings in which the characters are arranged alphabetically, e.g. "ab", but not "ba". Here's my attempt: (.)[\1-z]. It captures the first character and uses that for the beginning of the range in the list. However, in the [], \1 means U 0001, so it matches any two characters:
>>> re.search("(.)[\1-z]", "ab")
<re.Match object; span=(0, 2), match='ab'>
>>> re.search("(.)[\1-z]", "ba")
<re.Match object; span=(0, 2), match='ba'>
How can I backref a captured character in a character list?
CodePudding user response:
You'll have to spell it out completely, i.e a*b*c*d*......
Here is how you could do that:
regex = "(?=.)" "*".join(map(chr, range(97, 123))) "*"
s = "afkdiolsieyrnbsgdysoepkzavfz"
print(re.findall(regex, s))
CodePudding user response:
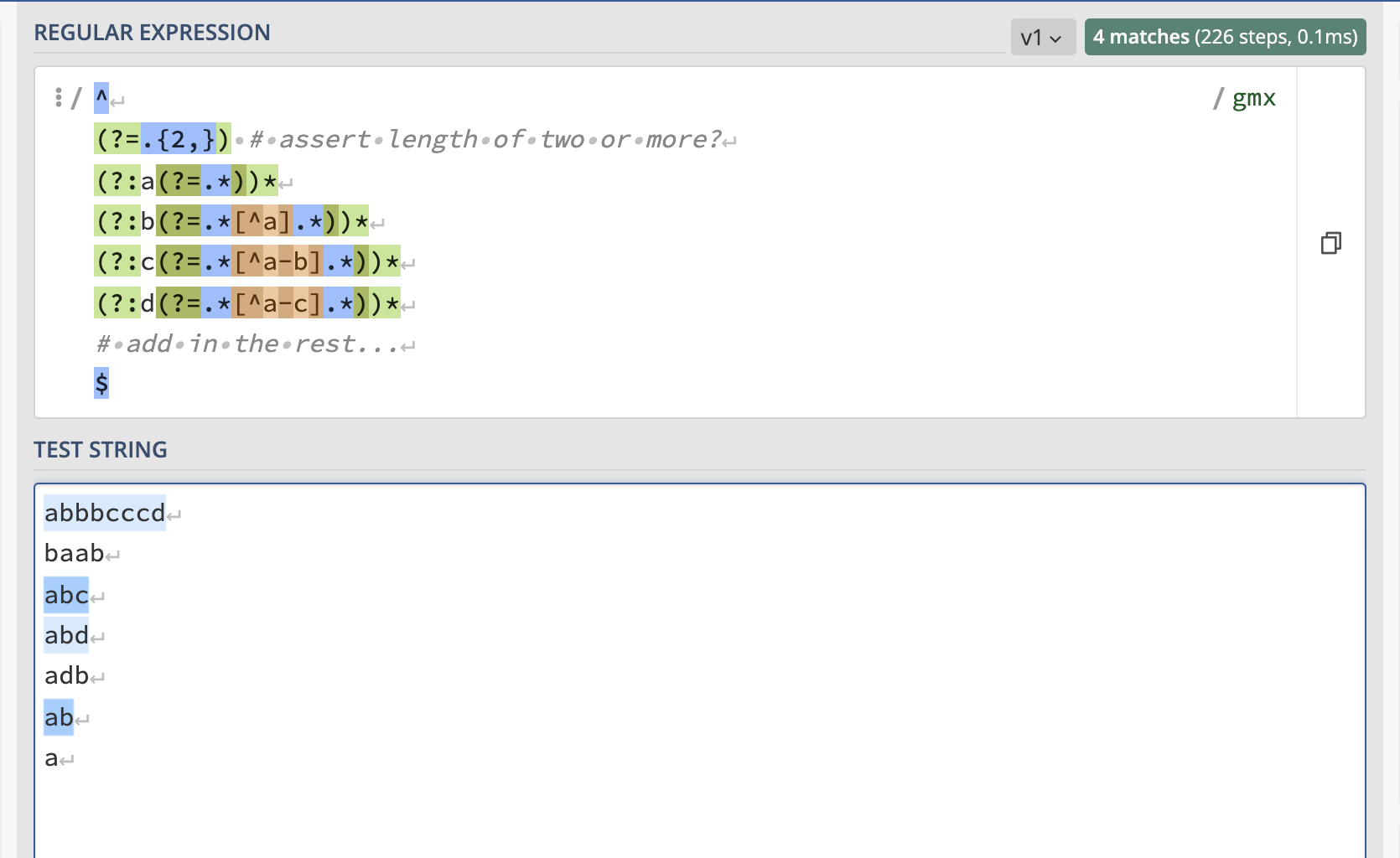
I suppose you could create a long regex which just checks each letter to make sure it's not succeeded by a letter of lower lexicographic rank. For example:
^
(?=.{2,}) # assert length of two or more?
(?:a(?=.*))*
(?:b(?=.*[^a].*))*
(?:c(?=.*[^a-b].*))*
(?:d(?=.*[^a-c].*))*
# add in the rest...
$
Here would be a