I want to get some information from tweets posted on the platform StockTwits.
Here you can see an example tweet: 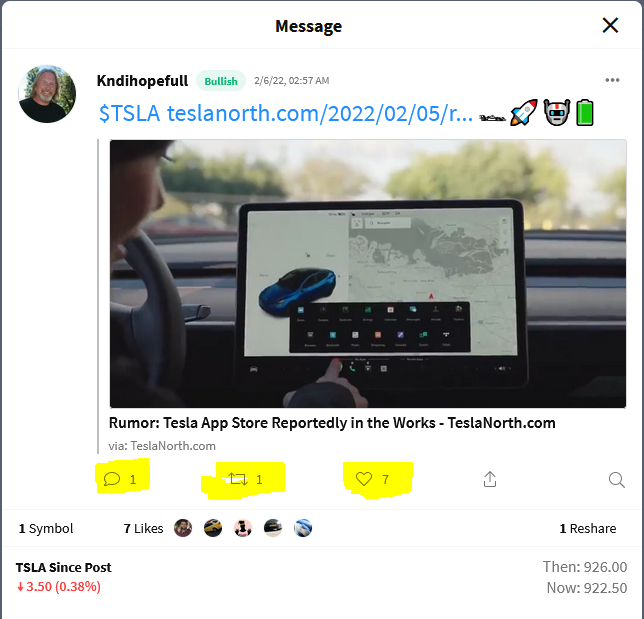
I think this is possible with the RSelenium-package. However, I am not really getting anywhere with my approach.
Can someone help me?
library(RSelenium)
url<- "https://stocktwits.com/Kndihopefull/message/433815546"
# RSelenium with Firefox
rD <- RSelenium::remoteDriver(browser="firefox", port=4546L)
remDr <- rD[["client"]]
remDr$navigate(url)
Sys.sleep(4)
# get the page source
web <- remDr$getPageSource()
web <- xml2::read_html(web[[1]])
I would like to have a list (or a data set) as a result, which looks like this:
$Reply
[1] 1
$Reshare
[1] 1
$Like
[1] 7
Many thanks in advance!
CodePudding user response:
To get required info we can do,
library(rvest)
library(dplyr)
library(RSelenium)
#launch browser
driver = rsDriver(browser = c("firefox"))
url = "https://stocktwits.com/ArcherUS/message/434172145"
remDr <- driver$client
remDr$navigate(url)
#First we shall get the tags
remDr$getPageSource()[[1]] %>%
read_html() %>% html_nodes('.st_3kvJrBm') %>%
html_attr('title')
[1] "Reply" "Reshare" "Like" "Share" "Search"
#then the number associated with it
remDr$getPageSource()[[1]] %>%
read_html() %>% html_nodes('.st_3kvJrBm') %>%
html_text()
[1] "" "" "2" "" ""
The last two items Share and Search will be empty.
The faster approach would be by using rvest.
library(rvest)
url = "https://stocktwits.com/ArcherUS/message/434172145"
url %>%
read_html() %>% html_nodes('.st_3kvJrBm') %>%
html_attr('title')
url %>%
read_html() %>% html_nodes('.st_3kvJrBm') %>%
html_text()