The query below takes about a minute to run on my MySQL instance (running on a fairly beefy machine with 64G memory, 2T disc, 2.30Ghz CPU with 8 cores and 16 logical, and the query is running on localhost). This same query runs in less than a second on a SQL Server database I have access to. Unfortunately, I do not have access to the SQL Server host or the DBA, etc.
select min(visit_start_date)
from visit_occurrence;
The table has been set to ENGINE=MyISAM and default-storage-engine=INNODB and innodb_buffer_pool_size=16G are set in my.ini.
Is there some configuration I could be missing that would cause this query to run so slowly on MySQL? How can I fix it?
I have a large number of tables and queries I will need to support so I would really like to be able to fix this issue globally rather than having to create indexes everywhere I have slow queries.
The SQL Server database does not seem to have an index on the column being queried as shown below.
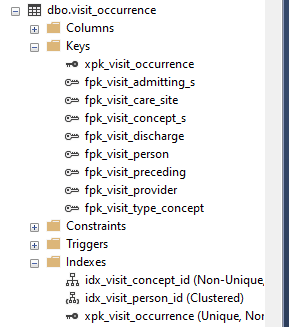
EDIT:
Untagged MS Sql Server, I had tagged it hoping for the help of our MS Sql Server colleagues with information that Sql Server had some way of structuring data and/or queries that would make this type of query run faster on that platform v other such as MySql
Removed image of code to more closely conform with community standards
You never know if there is a magic go-faster button if you don't ask (ENGINE=MyISAM is sometimes kind of like a magic go-faster button for some queries in MySql). I'm kind of fishing for a potential hardware or clustering solution here. Is Apache Ignite a potential solution here?
Thanks again to the community for all of your support and help. I hope this fixes most of the issues that have been raised for this post.
SECOND EDIT: Is the partitioning/sharding described in the links below a potential solution here?
https://user3141592.medium.com/how-to-scale-mysql-42ebd2841fa6
https://dev.mysql.com/doc/refman/8.0/en/partitioning-overview.html
THIRD EDIT: A note on community standards.
Part of our community standards is explicitly to be welcoming, inclusive, and to be nice.
The MS Sql Server tag was used here as one of the systems I'm comparing is MS Sql Server. We're really working with very limited information here. I have two systems: My MySql system, which is knowable as I'm running it, and the MS Sql Server running the same database in someone else's system that I have very little information about (all I have is a read only sql prompt). I am comparing apples and oranges: The same query runs well on the orange (MS Sql Server) and does not run well on the apple (My MySql instance). I'd like to know why so I can make an informed decision about how to get my queries to run in a reasonable amount of time. How do I get my apple to look like an orange? Do I switch to MS Sql Server? Do I need to deploy on different hardware? Is the other system running some kind of in memory caching system on top of their database instance? Most of these possibilities would require a non trivial amount of time to explore and validate. So yes, I would like help from MS Sql Server experts that might know if there are caching options, transactional v warehouse options, etc. that could be set that would make a world of difference, that would be magic go-fast buttons.
The magic go-fast button comment was perhaps a little bit condescending.
The picture showing the indexes was shown as I was just trying to make the point that the other system does not seem to have an index on the column being queried. I this case a picture was worth a thousand words.
CodePudding user response:
If the table says ENGINE=MyISAM, then that is what counts. In almost all cases, this is a bad choice. innodb_buffer_pool_size=16G is not relevant except that it robs memory from MyISAM.
default-storage-engine=INNODB is relevant only when creating a table explicitly specifying the ENGINE=.
Are some of your tables MyISAM and some are InnoDB? How much RAM do you have?
Most performance solutions necessarily involve an INDEX. Please explain why you can't afford an index. It could turn that query into less than 10ms, regardless of the number of rows in the table.
Sorry, but I don't accept "rather than having to create indexes everywhere I have slow queries".
Changing tables from MyISAM to InnoDB will, in some cases help with performance. Suggest you change the engine as you add the indexes.
Show us some more queries, we can help you decide what indexes are needed. select min(visit_start_date) from visit_occurrence; needs INDEX(date); other queries may not be so trivial. Do not fall into the trap of "indexing every column".
More
In MySQL...
A single connection only uses one core, so more cores only helps when you have more connections. (Some tiny exceptions exist in MySQL 8.0.)
Partitioning rarely helps with performance; do use that without getting advice. (PS:
BY RANGEis perhaps the only useful variant.)Replication is for read-scaling (and backup and ...)
Sharding is for write-scaling. It requires a bunch of extra architectural things -- such as routing queries to the appropriate servers. (MariaDB has Spider and FederatedX as possible tools.) In any case, sharding is a non-trivial undertaking.
Clustering is for HA (High Availability, auto-failover, etc), while helping some with read and write scaling. Cf: Galera, InnoDB Cluster.
Hardware is rarely more than a temporary solution to performance issues.
Caching leads to potentially inconsistent results, so beware. Also, consider my mantra "don't bother putting a cache in front of a cache".
(I can advise further on any of these topics.)
CodePudding user response:
Whether in MyISAM or InnoDB. or even SQL Server, your query
select min(visit_start_date) from visit_occurrence;
can be satisfied almost instantaneously by this index, because it uses a so-called loose index scan.
CREATE INDEX visit_start_date ON visit_occurrence (visit_start_date);
A query with an aggregate function like MIN() is always a GROUP BY query. But if the GROUP BY clause isn't present in the SQL statement, the server groups by the entire table.
You mentioned a query that can be satisfied immediately when using MyISAM. That's SELECT COUNT(*) FROM whatever_table. Behind the scenes MyISAM keeps table metadata showing the total number of rows in the table, so that query comes back right away. The transactional storage engine InnoDB doesn't do that. It supports so much concurrency that its designers didn't include the total row count in their metadata, because it would be wrong in so many circumstances that it wasn't worth the risk.
Index design isn't a black art. But it is an art informed by the kind of measurements we get from EXPLAIN (or ANALYZE or EXPLAIN ANALYZE). A basic truth of database-driven apps (in any make of database server) is that indexing needs to be revisited as the app grows. The good news: changing, adding, or dropping indexes doesn't change your data.