I have two files, fileA and fileB. These are text files, each containing essentially one long string (a series of paragraphs).
I want to be able to show only the 'words' in fileB that are newly added/not contained in fileA. Browsing this forum I saw saw git diff as a suggested approach - using its word-diff argument, highlights in green the new words in fileB nicely.
I was wondering if there's a way to take this output and extract only the new additions in fileB, so that I could place this in a separate text file. To maybe help make this clearly, what I'm envisioning is something like the diff command given here as an answer (diff -U $(wc -l < fileA) fileA fileB | sed -n 's/^-//p' > fileC, 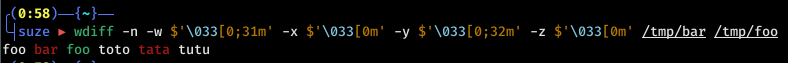
CodePudding user response:
You're looking for --word-diff=porcelain to make extracting the individual changes easy to code. Each changed line is printed as a series of unchanged, removed and added words runs, with the line boundaries shown as a separate ~ line.