I have 2 pandas data-frames, with 2 columns namely index and date. Some of the dates are missing from the first data-frame, and those values can be obtained from the second data-frame corresponding to the index. I tried using pd.concat, pd.merge and pd.join etc but those doesn't seem to give me the results that I want. Here is the table.
df1 = 
df2 = 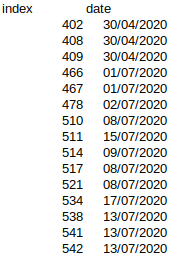
CodePudding user response:
Have you tried df1 = df1.update(df2)?
Although the update funtion will not increase the size of df1, it only updates the missing values or the values that were already there.
CodePudding user response:
Since there was no reproducible dataframe, I tried the code below with running on generated data, but I think it would work fine for your code too:
import pandas as pd
df1 = pd.DataFrame({"date": [None, None, None, "01/01/2022"], "index":[402,402,403,404]})
df2 = pd.DataFrame({"date": ["16/05/2020", "18/07/2021", "13/08/2022", "26/07/2020"], "index":[402,405,403,404]})
df1.set_index("index", inplace=True)
df2.set_index("index", inplace=True)
for index, row in df1.iterrows():
if row["date"] != row["date"] or row["date"] == None:
df1.loc[index , "date"] = df2.loc[index]["date"]
df1
Output
| index | date |
|---|---|
| 402 | 16/05/2020 |
| 402 | 16/05/2020 |
| 403 | 13/08/2022 |
| 404 | 01/01/2022 |
Note that row["date"] != row["date"] is used when a value of a cell is nan and has the type of float. nan values are not equal even to themselves!
CodePudding user response:
You can try this solution:
import pandas as pd
import numpy as np
# initialize list of lists
df1 = [[402, '15/05/2020'], [408, np.nan], [408, '14/05/2020']]
df2 = [[402, '16/05/2020'], [408, '10/05/2020'], [409, '13/05/2020']]
# Create the pandas DataFrame
df1 = pd.DataFrame(df1, columns=['index', 'date'])
df2 = pd.DataFrame(df2, columns=['index', 'date'])
df1.set_index("index", inplace=True)
df2.set_index("index", inplace=True)
for index, row in df1.iterrows():
if row["date"] != row["date"]:
row["date"] = df2.loc[index]["date"]
Output:
index
402 15/05/2020
408 10/05/2020
408 14/05/2020
With this solution only the rows whose date is nan or null are updated with the corresponding value on the other dataframe.