I have a script that tries to get a Twitter handle's name. Here's the script:
import requests, re, bs4, lxml
from bs4 import BeautifulSoup
url = 'https://web.archive.org/web/20150623154546/https:/twitter.com/biz/status/600839913286672384'
r = requests.get(url).text
c = re.compile('.*fullname js-action-profile-name show-popup-with-id.*')
user = bs4.BeautifulSoup(r, "lxml").find("strong", {"class": c}).getText()
print(user)
Now, this is what the Element Inspector looks like:
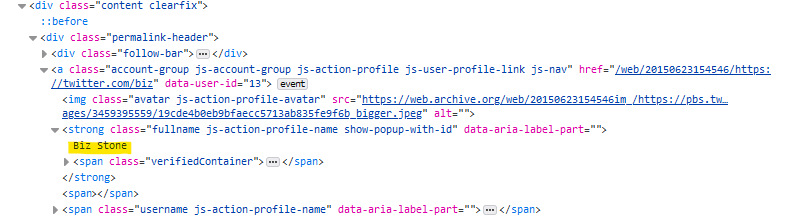
I want to print only the text highlighted above in yellow (Biz Stone). However, this is my Python output:
Biz StoneVerified account
As you can see, the string "Verified account" is appended, for an unfathomable reason. The text in Inspect Element only shows "Biz Stone". Why does this occur, and how can I fix it?
I tried fixing it by following the instructions in this solution and this one. Unfortunately, the first one (adding text=True) printed random people's names, while adding to it "recursive=False" as in the second solution prints nothing.
CodePudding user response:
It adds Verified account because within the Strong tag is a span tag which likely has text within it somewhere that says Verified account
.getText() will get all the text within that tag
When I've encountered this issue, I've got the text from the span tag first then got the text from the strong tag and then replaced the span text with a blank string
CodePudding user response:
get_text gets all text inside the found tag ("strong" tag contains "span" tags as children, one of which has "Verified account" as text). However, since you don't want to look through the children of "strong" tag, you can do that by setting the parameter recursive=False:
soup = BeautifulSoup(r, "lxml")
out = soup.find("strong", {'class': c}).find(text=True, recursive=False)
Output:
'Biz Stone'