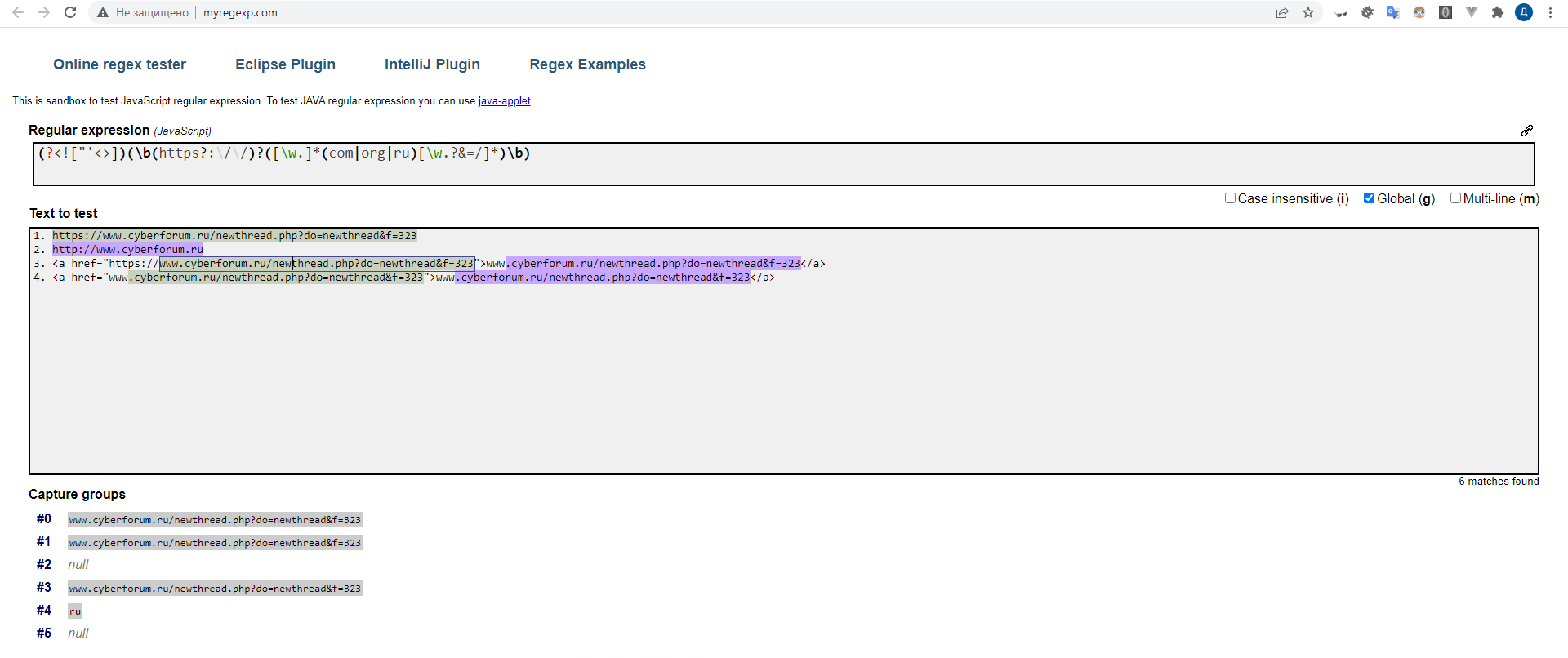
Help me, please, write regular expression for find all links (.com|.org|.ru) without tag <a> in text.
Example text:
1. https://www.cyberforum.ru/newthread.php?do=newthread&f=323
2. www.cyberforum.ru
3. <a href="https://www.cyberforum.ru/newthread.php?do=newthread&f=323">www.cyberforum.ru/newthread.php?do=newthread&f=323</a>
4. <a href="www.cyberforum.ru/newthread.php?do=newthread&f=323">www.cyberforum.ru/newthread.php?do=newthread&f=323</a>
Items 1,2 should be match with regular expression but 3,4 - no.
I tryed /(?<!["'<>])(\b(https?://)?([\w.](com|org|ru)[\w.?&=/])\b)/ but it is not work correctly.
CodePudding user response:
My solution:
/**
* Wraps links in <a></a> tag.
* Skip links which are in href or in <a></a> tag already.
*
* @param string $text
* @return string
*/
private static function replaceLinks(string $text): string
{
return preg_replace_callback(
'/\b(https?:\/\/)?([\w.-]*(\.com|\.org|\.ru|\.local)[\w.?&=\/]*)\b/',
function ($matches) use ($text) {
// checks previous char, skip links which are in href or in <a></a> tag
$previousChar = $matches[0][1] > 0 ? $text[--$matches[0][1]] : '';
if (!in_array($previousChar, ['"', '\'', '<', '>', ';'])) {
return "<a target='_blank' href=\"{$matches[0][0]}\">{$matches[0][0]}</a>";
}
// without replace
return $matches[0][0];
},
$text,
-1,
$cont,
PREG_OFFSET_CAPTURE
);
}
CodePudding user response:
Here is a way that combines DOM with RegEx. It restricts the change to the text content of element nodes inside the body and avoids modifying other nodes like comments or attributes.
What happens:
- Iterate over the text nodes
/html/body//text()[not(ancestor::a)], avoid existing link elements - Use preg_split() to separate the text by matching http(s) URLs
- Iterate over that list and add them (to a fragment) as a link if it is an URL or as a text node if not.
- Replace the original text node with the new fragment.
$html = <<<'HTML'
<html>
<body>
Some link http://example.tld to replace.
<div>Another link http://example.tld/another to replace.</div>
<a href="http://example.tld/in-link">http://example.tld/in-link</a>
</body>
</html>
HTML;
$document = new DOMDocument();
$document->loadHTML($html);
$xpath = new DOMXpath($document);
$linkPattern = '\b(?:https?:\/\/)(?:[\w.?&=\/-]*)\b';
$splitPattern = '(('.$linkPattern.'))';
$matchPattern = '(^'.$linkPattern.'$)';
// iterate over text nodes inside the body
$expression = '/html/body//text()[not(ancestor::a)]';
foreach ($xpath->evaluate($expression) as $textNode) {
// split the text content at the search string and capture any part
$parts = preg_split(
$splitPattern,
$textNode->textContent,
-1,
PREG_SPLIT_DELIM_CAPTURE
);
// here should be at least two parts
if (count($parts) < 2) {
continue;
}
// fragments allow to treat several nodes like one
$fragment = $document->createDocumentFragment();
foreach ($parts as $part) {
// it's an URL
if (preg_match($matchPattern, $part)) {
// create the new a
$fragment->appendChild(
$a = $document->createElement('a')
);
$a->setAttribute('href', $part);
$a->textContent = $part;
} else {
// add the part as a new text node
$fragment->appendChild($document->createTextNode($part));
}
}
// replace the text node with the fragment
$textNode->parentNode->replaceChild($fragment, $textNode);
}
echo $document->saveHTML();