I'm trying to iterate over a large DataFrame that has 32 fields, 1 million plus rows.
What i'm trying to do is iterate over each row, and check whether any of the rest of the rows have duplicate information in 30 of the fields, while the other two fields have different information.
I'd then like to store the the ID info. of the rows that meet these conditions.
So far i've been trying to figure out how to check two rows with the below code, it seems to work when comparing single columns but throws an error when I try more than one column, could anyone advise on how best to approach?
for index in range(len(df)):
for row in range(index, len(df)):
if df.iloc[index][1:30] == df.iloc[row][1:30]:
print(df.iloc[index])
CodePudding user response:
As a general rule, 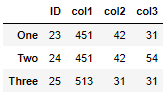
Find which rows are duplicates in col1 and col2. Note that the default is that the first instance is not marked as a duplicate, but later duplicates are. This behaviour can be changed as described in the documentation I linked to above.
mask = sub_df.duplicated(["col1", "col2"])
This looks like:
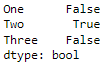
Now, filter using the mask.
sub_df["ID"][sub_df.duplicated(["col1", "col2"])]

Of course, you can do the last two steps in one line.