Example of numbers

I am using the standard pytesseract img to text. I have tried with digits only option 90% of the time it is perfect but above is a example where it goes horribly wrong! This example produced no characters at all
As you can see there are now letters so language option is of no use, I did try adding some text in the grabbed image but it still goes wrong.
I increased the contrast using CV2 the text has been blurred upstream of my capture
Any ideas on increasing accuracy?
CodePudding user response:
Here's a simple approach using OpenCV and Pytesseract OCR. To perform OCR on an image, it's important to preprocess the image. The idea is to obtain a processed image where the text to extract is in black with the background in white. To do this, we can convert to 
Convert to grayscale -> apply sharpening filter

Otsu's threshold
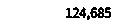
Result from Pytesseract OCR
124,685
Code
import cv2
import numpy as np
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
# Load image, grayscale, apply sharpening filter, Otsu's threshold
image = cv2.imread('1.png')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
sharpen_kernel = np.array([[-1,-1,-1], [-1,9,-1], [-1,-1,-1]])
sharpen = cv2.filter2D(gray, -1, sharpen_kernel)
thresh = cv2.threshold(sharpen, 0, 255, cv2.THRESH_BINARY_INV cv2.THRESH_OTSU)[1]
# OCR
data = pytesseract.image_to_string(thresh, lang='eng', config='--psm 6')
print(data)
cv2.imshow('sharpen', sharpen)
cv2.imshow('thresh', thresh)
cv2.waitKey()