My need in short: I want to refresh references to text marks in a docx document with Apache POI 5.
Context: In a docx document, my system replaces text in placeholders (e.g. "${myplaceholder}"). Some of these placeholders are within text marks. This works fine.
In the document there are references to the text marks. After replacing placeholders (within the text mark), I open the docx document, select everything with Ctrl A and hit F9. Then all references are updated and contain the text from the referenced text marks / placeholders.
Problem/Quest: I do not want (the system users) to hit Ctrl A / F9 to update the references.
Question: Is there a way either (a) to force Microsoft Word to refresh all references (like this is feasible for xlsx files with Apache POI) or (b) to refresh all references in Apache POI 5?
Update simple code example:
This is the content of the input docx document (where the second "${firstname}" is a reference to the first "${firstname}" (marked in MS Word as a text mark)):

This is some code that adds some text to the "firstname" placeholder:
File inputDocxFile = new File("Reference.docx");
File outputDocxFile = new File("Reference_output.docx");
XWPFDocument document = new XWPFDocument(new FileInputStream(inputDocxFile));
for (XWPFParagraph paragraph : document.getParagraphs()) {
System.out.println("Paragraph: " paragraph.getText());
for (XWPFRun run : paragraph.getRuns()) {
System.out.println("RUN: " run.text());
if (paragraph.getText().equals("${firstname}") && run.text().equals("firstname")) {
run.setText("World");
}
}
}
FileOutputStream fos = new FileOutputStream(outputDocxFile);
document.write(fos);
fos.close();
document.close();
And this is the output (without refreshed reference):
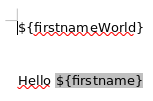
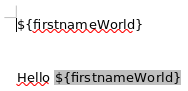
After hitting Ctrl A / F9 this is the refreshed (and expected) output:
CodePudding user response:
The whole problem goes away when the text-replacement works correctly.
The problem here is how Word stores texts in different text runs. Not only different formatting splits text in different text runs, also marking grammar and spelling check problems do and multiple other things. So one can impossible predict how a text gets split into text runs when typed in Word. That's why your text-replacement approach is not good.
Apache POI provides 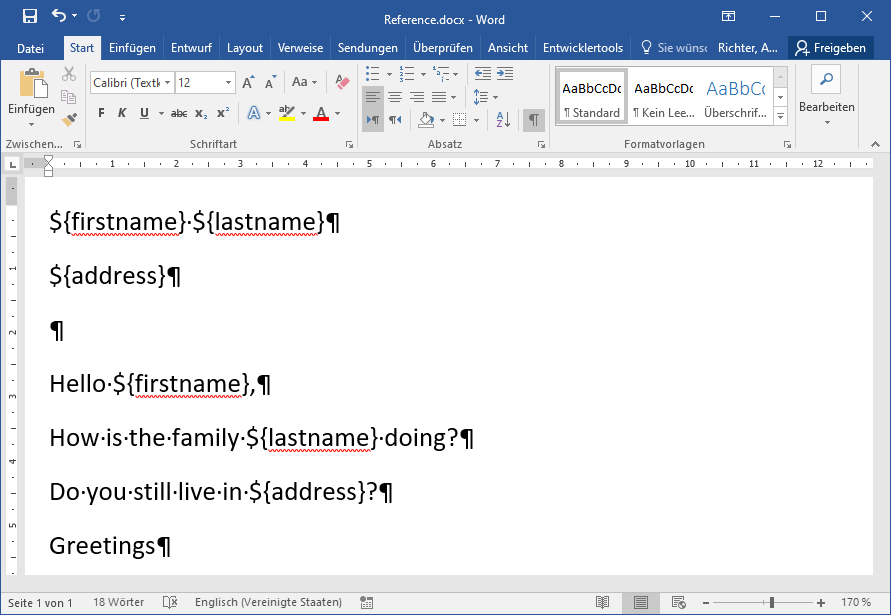
There ${firstname}, ${lastname} and ${address} in head are bookmarked as firstname. lastname and address. And their occurences in text are references as { REF firstname } , { REF lastname} and { REF address}
After running following code:
import java.io.*;
import org.apache.poi.xwpf.usermodel.*;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.*;
public class WordReplaceTextSegment {
static public void replaceTextSegment(XWPFParagraph paragraph, String textToFind, String replacement) {
TextSegment foundTextSegment = null;
PositionInParagraph startPos = new PositionInParagraph(0, 0, 0);
while((foundTextSegment = paragraph.searchText(textToFind, startPos)) != null) { // search all text segments having text to find
//System.out.println(foundTextSegment.getBeginRun() ":" foundTextSegment.getBeginText() ":" foundTextSegment.getBeginChar());
//System.out.println(foundTextSegment.getEndRun() ":" foundTextSegment.getEndText() ":" foundTextSegment.getEndChar());
// maybe there is text before textToFind in begin run
XWPFRun beginRun = paragraph.getRuns().get(foundTextSegment.getBeginRun());
String textInBeginRun = beginRun.getText(foundTextSegment.getBeginText());
String textBefore = textInBeginRun.substring(0, foundTextSegment.getBeginChar()); // we only need the text before
// maybe there is text after textToFind in end run
XWPFRun endRun = paragraph.getRuns().get(foundTextSegment.getEndRun());
String textInEndRun = endRun.getText(foundTextSegment.getEndText());
String textAfter = textInEndRun.substring(foundTextSegment.getEndChar() 1); // we only need the text after
if (foundTextSegment.getEndRun() == foundTextSegment.getBeginRun()) {
textInBeginRun = textBefore replacement textAfter; // if we have only one run, we need the text before, then the replacement, then the text after in that run
} else {
textInBeginRun = textBefore replacement; // else we need the text before followed by the replacement in begin run
endRun.setText(textAfter, foundTextSegment.getEndText()); // and the text after in end run
}
beginRun.setText(textInBeginRun, foundTextSegment.getBeginText());
// runs between begin run and end run needs to be removed
for (int runBetween = foundTextSegment.getEndRun() - 1; runBetween > foundTextSegment.getBeginRun(); runBetween--) {
paragraph.removeRun(runBetween); // remove not needed runs
}
}
}
public static void main(String[] args) throws Exception {
XWPFDocument doc = new XWPFDocument(new FileInputStream("./Reference.docx"));
String[] textsToFind = {"${firstname}", "${lastname}", "${address}"}; // might be in different runs
String[] replacements = {"Axel", "Richter", "Somewhere in Germany"};
for (XWPFParagraph paragraph : doc.getParagraphs()) { //go through all paragraphs
for (int i = 0; i < textsToFind.length; i ) {
String textToFind = textsToFind[i];
if (paragraph.getText().contains(textToFind)) { // paragraph contains text to find
String replacement = replacements[i];
replaceTextSegment(paragraph, textToFind, replacement);
}
}
}
FileOutputStream out = new FileOutputStream("./Reference_output.docx");
doc.write(out);
out.close();
doc.close();
}
}
The Reference_output.docx looks like so:
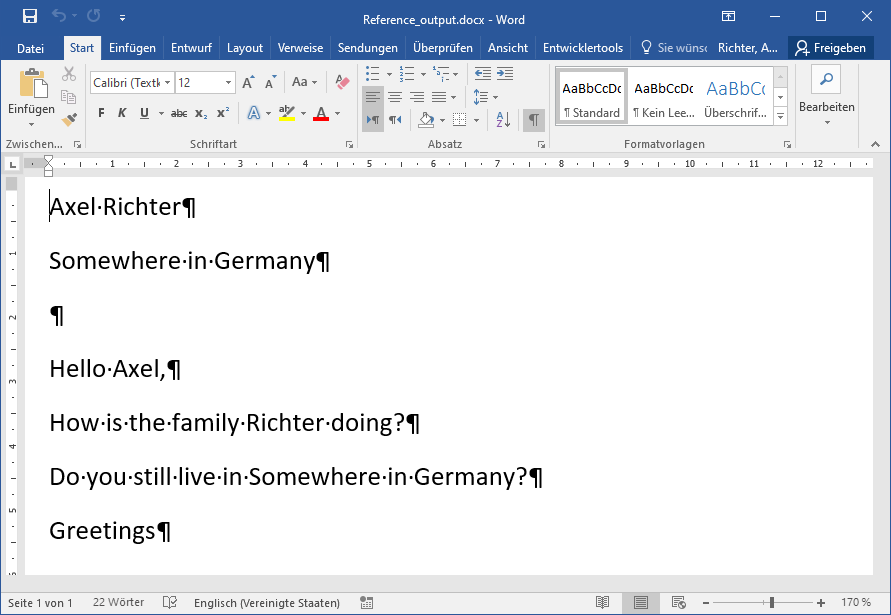
All replacements are done and the bookmarks and also the references to the bookmarks are still there.