Given this dataset:
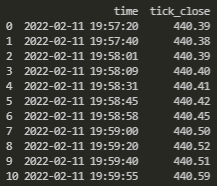
... I want to create open, high and low columns, resampled to the beginning minute of each row. Note that we cannot just simply use .resample() in this case. What I'm looking to end up with is a dataset that looks like this:
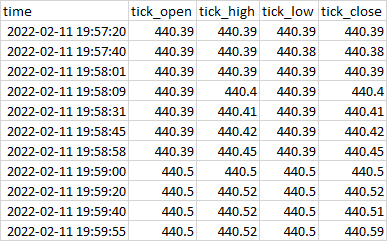
I'd like to NOT use a for loop for this, rather a column calculation for the open, high and low columns (unless there's an even faster way to do this, or if .resample() could somehow work in this case).
The time column is in pd.to_datetime() format.
I tried to do something like this for the max column:
tick_df['tick_high'] = tick_df[(tick_df['time'] >= tick_df['time'].replace(second=0)) & (tick_df['time'] <= tick_df['time'])].max()
...the logic here being, select the rows that are between the current datetime's time at the top of the minute (so 0 seconds), and going to the current row's datetime. So example would be between 2022-02-11 19:57:00 to 2022-02-11 19:57:20 if looking at the first row.
However when I try this, I get the error:
TypeError: replace() got an unexpected keyword argument 'second'
...because technically I'm using pandas' replace function, not the datetime.replace function. So I also tried adding in .dt before the .replace and got this one:
AttributeError: 'DatetimeProperties' object has no attribute 'replace'
Any suggestions on how I can achieve the desired output? For reference, here is my reproducible code:
from datetime import datetime
import pandas as pd
# create a mock tick df
tick_time = ["2022-02-11 19:57:20",
"2022-02-11 19:57:40",
"2022-02-11 19:58:01",
"2022-02-11 19:58:09",
"2022-02-11 19:58:31",
"2022-02-11 19:58:45",
"2022-02-11 19:58:58",
"2022-02-11 19:59:00",
"2022-02-11 19:59:20",
"2022-02-11 19:59:40",
"2022-02-11 19:59:55"]
tick_time = pd.to_datetime(tick_time)
tick_df = pd.DataFrame(
{
"time": tick_time,
"tick_close": [440.39,440.38,440.39,440.40,440.41,440.42,440.45,440.50,440.52,440.51,440.59],
},
)
print(tick_df)
# Attempt to resample ticks ohlc from the beginning of each minute
tick_df['tick_high'] = tick_df[(tick_df['time'] >= tick_df['time'].dt.replace(second=0)) & (tick_df['time'] <= tick_df['time'])].max()
I will be back tomorrow to review answers. Thanks!
CodePudding user response:
Base on GitHub ticket we can do with map
tick_df['time'].map(lambda x : x.replace(second=0))
To get your output
cond1 = tick_df['time'].map(lambda x : x.replace(second=0))
tick_df['tick_high'] = [tick_df.loc[(tick_df['time']>=x) & (tick_df['time']<=y) ,'tick_close'].max() for x, y in zip(cond1,tick_df['time'])]
tick_df
Out[552]:
time tick_close tick_high
0 2022-02-11 19:57:20 440.39 440.39
1 2022-02-11 19:57:40 440.38 440.39
2 2022-02-11 19:58:01 440.39 440.39
3 2022-02-11 19:58:09 440.40 440.40
4 2022-02-11 19:58:31 440.41 440.41
5 2022-02-11 19:58:45 440.42 440.42
6 2022-02-11 19:58:58 440.45 440.45
7 2022-02-11 19:59:00 440.50 440.50
8 2022-02-11 19:59:20 440.52 440.52
9 2022-02-11 19:59:40 440.51 440.52
10 2022-02-11 19:59:55 440.59 440.59
CodePudding user response:
IIUC, do you want?
i = pd.Index(['first','cummax','cummin'])
tick_df.join(
pd.concat([tick_df.groupby(pd.Grouper(key='time', freq='T'))['tick_close']
.transform(c)
.rename(f'tick_{c}')
for c in i], axis=1)
)
Output:
time tick_close tick_first tick_cummax tick_cummin
0 2022-02-11 19:57:20 440.39 440.39 440.39 440.39
1 2022-02-11 19:57:40 440.38 440.39 440.39 440.38
2 2022-02-11 19:58:01 440.39 440.39 440.39 440.39
3 2022-02-11 19:58:09 440.40 440.39 440.40 440.39
4 2022-02-11 19:58:31 440.41 440.39 440.41 440.39
5 2022-02-11 19:58:45 440.42 440.39 440.42 440.39
6 2022-02-11 19:58:58 440.45 440.39 440.45 440.39
7 2022-02-11 19:59:00 440.50 440.50 440.50 440.50
8 2022-02-11 19:59:20 440.52 440.50 440.52 440.50
9 2022-02-11 19:59:40 440.51 440.50 440.52 440.50
10 2022-02-11 19:59:55 440.59 440.50 440.59 440.50