I have an extensive data frame with 30 columns and 10000 rows. Today I want to focus in two columns: languages and languages2:
languages languages2
Spanish NA
Spanish NA
Other (specify) French
Other (specify) German
Other (specify) Russian
English NA
Other (specify) Portuguese
English NA
(...)
This is what I need:
languages
Spanish
Spanish
French
German
Russian
English
Portuguese
English
(...)
I am looking for an answer using mutate function from dplyr
CodePudding user response:
For a bigger data you may want to control for additional scenarios, like preventing replacing the data with NA and laving the Other value. Also if there may be a merit for addressing scenarios where the first column may contain Other() or Other, lang. You may want to consider using a regular expression or pre-processing the first column.
library("tidyverse")
dta <- tribble(
~lang1, ~lang2,
"Spanish", NA,
"Other", "English",
"Other", NA
)
mutate(dta, lang1 = case_when(
grepl("^Other,*", lang1) & !is.na(lang2) ~ lang2,
TRUE ~ lang1
))
CodePudding user response:
Using dplyr, we could replace Other (specify) with NA, then use coalesce:
library(dplyr)
df %>%
mutate(languages = coalesce(na_if(languages, "Other (specify)"), languages2)) %>%
select(languages)
Output
languages
1 Spanish
2 Spanish
3 French
4 German
5 Russian
6 English
7 Portuguese
8 English
A tidyverse option is to use str_replace_all to replace Other (specify) with the value from languages2.
library(tidyverse)
df %>%
mutate(languages = str_replace_all(languages,"Other \\(specify\\)", languages2)) %>%
select(languages)
Data
df <- structure(list(languages = c("Spanish", "Spanish", "Other (specify)",
"Other (specify)", "Other (specify)", "English", "Other (specify)",
"English"), languages2 = c(NA, NA, "French", "German", "Russian",
NA, "Portuguese", NA)), class = "data.frame", row.names = c(NA,
-8L))
Benchmark
However, if you have a lot of data and need something faster, then you might consider base R, which would be faster than dplyr or data.table.
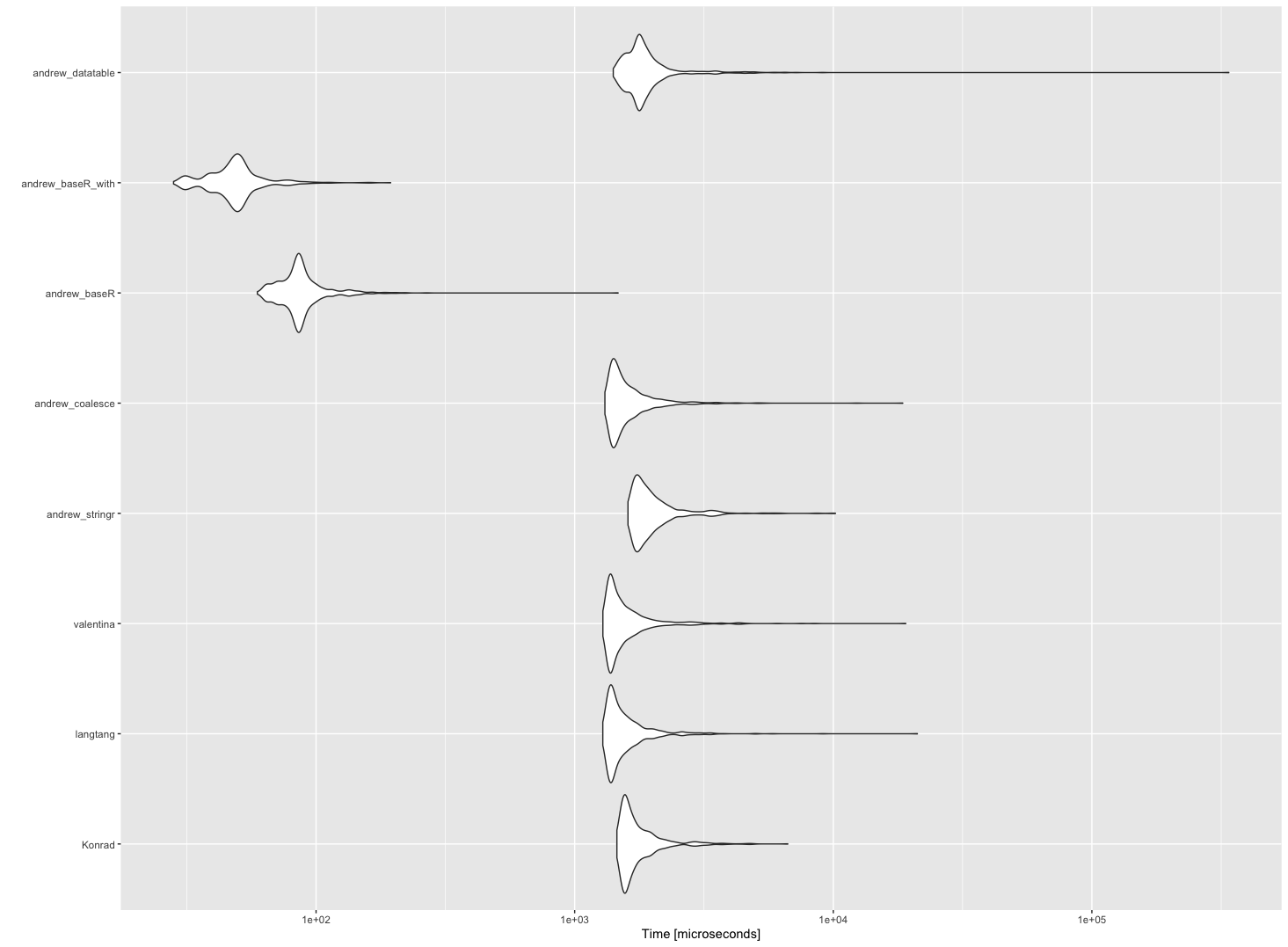
bm <- microbenchmark::microbenchmark(Konrad = mutate(df, languages = case_when(
grepl("^Other,*", languages) & !is.na(languages2) ~ languages2,
TRUE ~ languages
)),
langtang = df %>%
mutate(languages=if_else(languages=="Other (specify)", languages2, languages)),
valentina = df %>%
mutate(languages=if_else(!is.na(languages2), languages2, languages)),
andrew_stringr = df %>%
mutate(languages = str_replace_all(languages,"Other \\(specify\\)", languages2)),
andrew_coalesce = df %>%
mutate(languages = coalesce(na_if(languages, "Other (specify)"), languages2, 'Other (specify)')),
andrew_baseR = {df1 <- df; df1[df1$languages == "Other (specify)", "languages"] <- df1[df1$languages == "Other (specify)", "languages2" ]},
andrew_baseR_with = {df2 <- df; df2$languages <- with( df2, ifelse( languages == "Other (specify)", languages2, languages ) )},
andrew_datatable = {dt <- as.data.table(df); dt[languages == "Other (specify)", languages := languages2 ]},
times = 1000)
CodePudding user response:
data %>%
mutate(languages=if_else(languages=="Other (specify)", languages2, languages)
CodePudding user response:
Another possibility (if you prefer the check to be over the 2nd column instead of the 1st):
library(dplyr)
df <- data.frame(languages=c("Spanish","Spanish","Other (specify)","Other (specify)","Other (specify)","English","Other (specify)","English"),languages2=c(NA,NA,"French","German","Russian",NA,"Portuguese",NA))
df %>%
mutate(languages=if_else(!is.na(languages2), languages2, languages))
languages languages2
1 Spanish <NA>
2 Spanish <NA>
3 French French
4 German German
5 Russian Russian
6 English <NA>
7 Portuguese Portuguese
8 English <NA>