I am trying to compute the MSE for every row in my dataframe,
Below is my code-
import pandas as pd
s={'AValues':[1,1,2,2],'month':[2016,2017,2018,2019],'fvalues':[55,66,77,88],'Fruits':['Apple','Mango','Orange','Banana']}
p=pd.DataFrame(data=s)
mse_df=pd.pivot_table(p,index='Fruits',columns='month',values=['AValues','fvalues'])
mse_df=mse_df.fillna(0)
This is how the dataframe output of above code looks like-
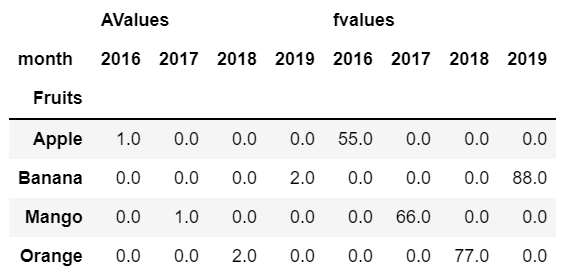
I wanted to calculate here mse for Apples, Banana, Mango and Orange i.e row by row. (AValues- actual values , fvalues- forecasted values)
I am trying the below code-
from sklearn.metrics import mean_squared_error
mean_squared_error(mse_df['AValues'],mse_df['fvalues'])
But, it's giving me the total mse and not individual or row by row.
Can you please help me on how the mse can be found out?
CodePudding user response:
I'm surprised this mean_square_error function you import doesn't have an axis kwarg. Instead, use numpy
import numpy as np
MSE = np.mean((mse_df['AValues'] - mse_df['fvalues'])**2, axis=ax)
where ax is the axis you want the mean to be calculated over. I'm not so familiar with pandas, but if they are the same shape as numpy arrays / matrices / similar, it will probably be axis=1, although it could be axis=0