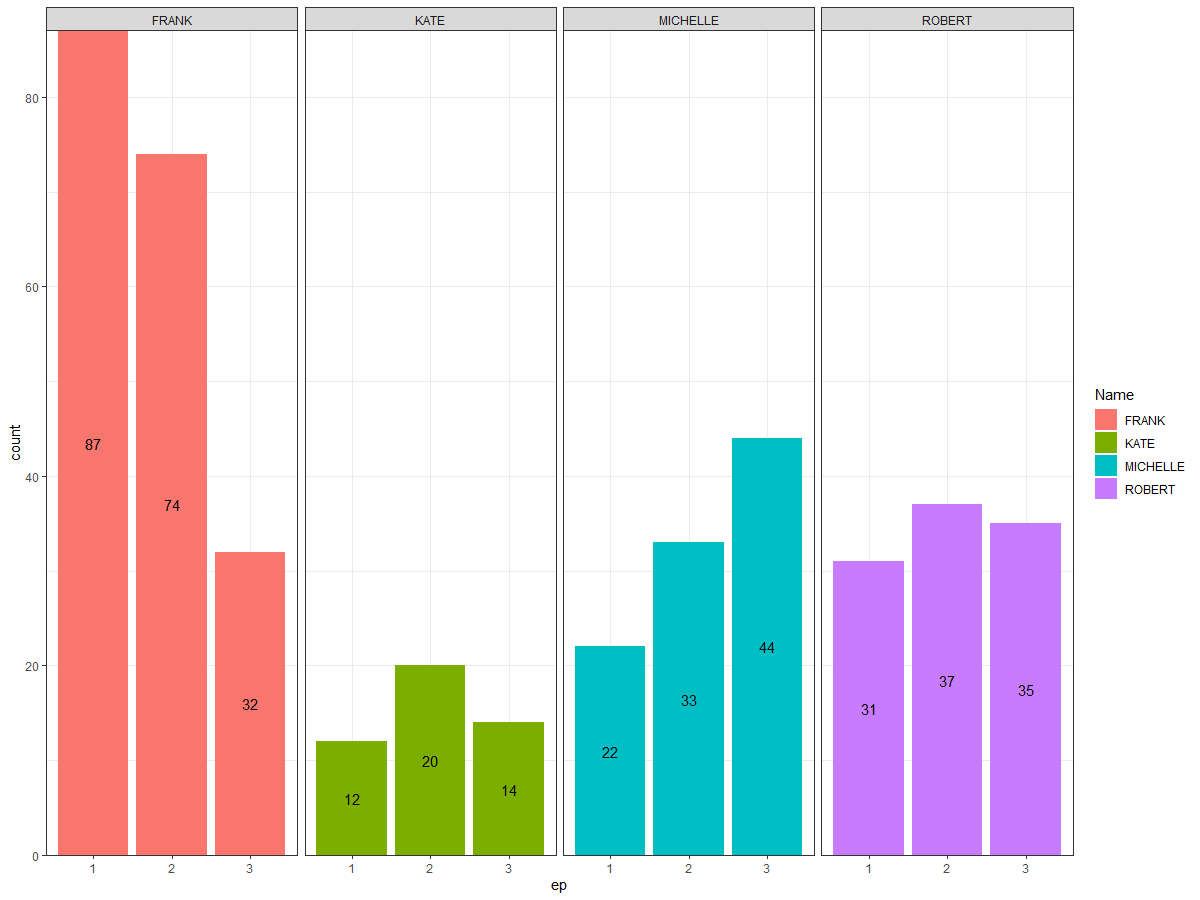
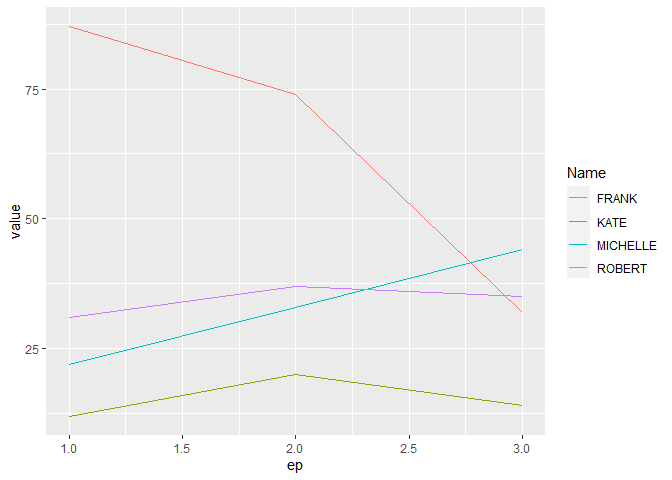
I have created the following plot:
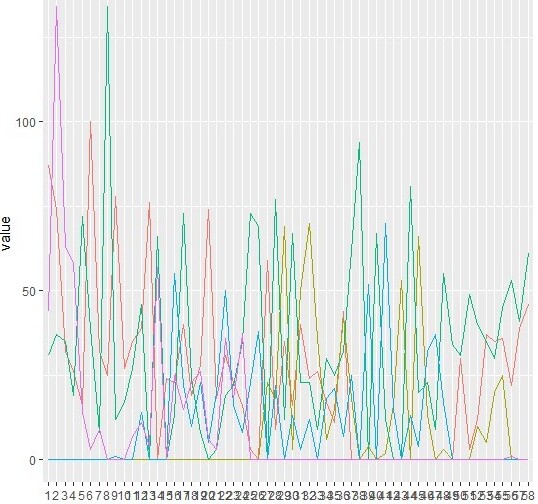
From a bigger version (5 rows, 58 columns) of this df:
df <- data.frame(row.names = c("ROBERT", "FRANK", "MICHELLE", "KATE"), `1` = c(31, 87, 22, 12), `2` = c(37, 74, 33, 20), `3` = c(35, 32, 44, 14))
colnames(df) <- c("1", "2", "3")
In the following manner:
df = df %>%
rownames_to_column("Name") %>%
as.data.frame()
df <- melt(df , id.vars = 'Name', variable.name = 'ep')
ggplot(df, aes(ep,value)) geom_line(aes(colour = Name, group=Name))
The plot kind of shows what I'd like to, but it really is a mess. Does anyone have a suggestion that would help me increasing its readability? Any help is very much appreciated!
CodePudding user response:
The best approach will really depend on what you're trying to understand or communicate with your plot. But here are a few options for visualizing lots of datapoints across a smallish number of cases. These are illustrated with a subset of the txhousing data included with ggplot2.
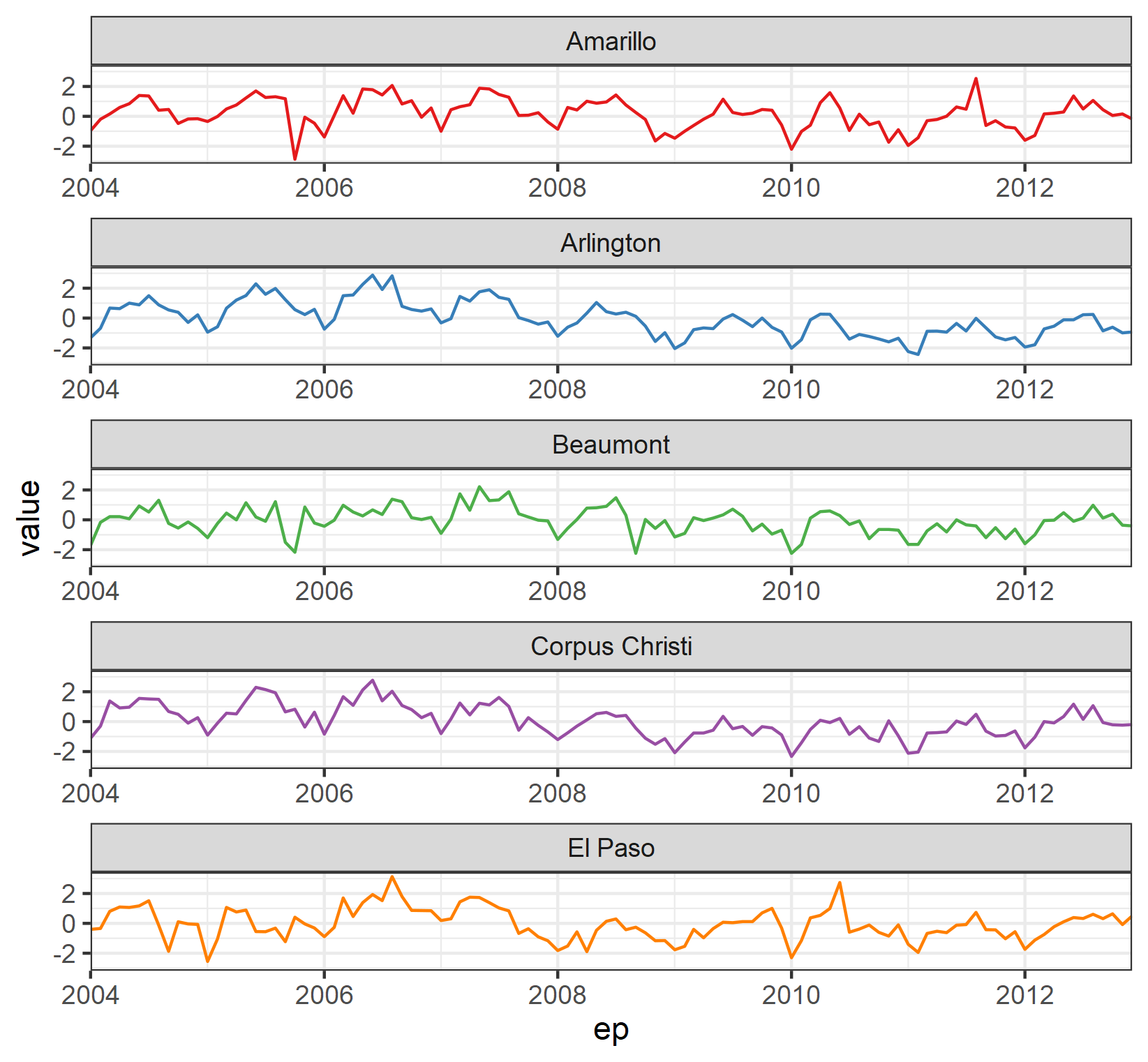
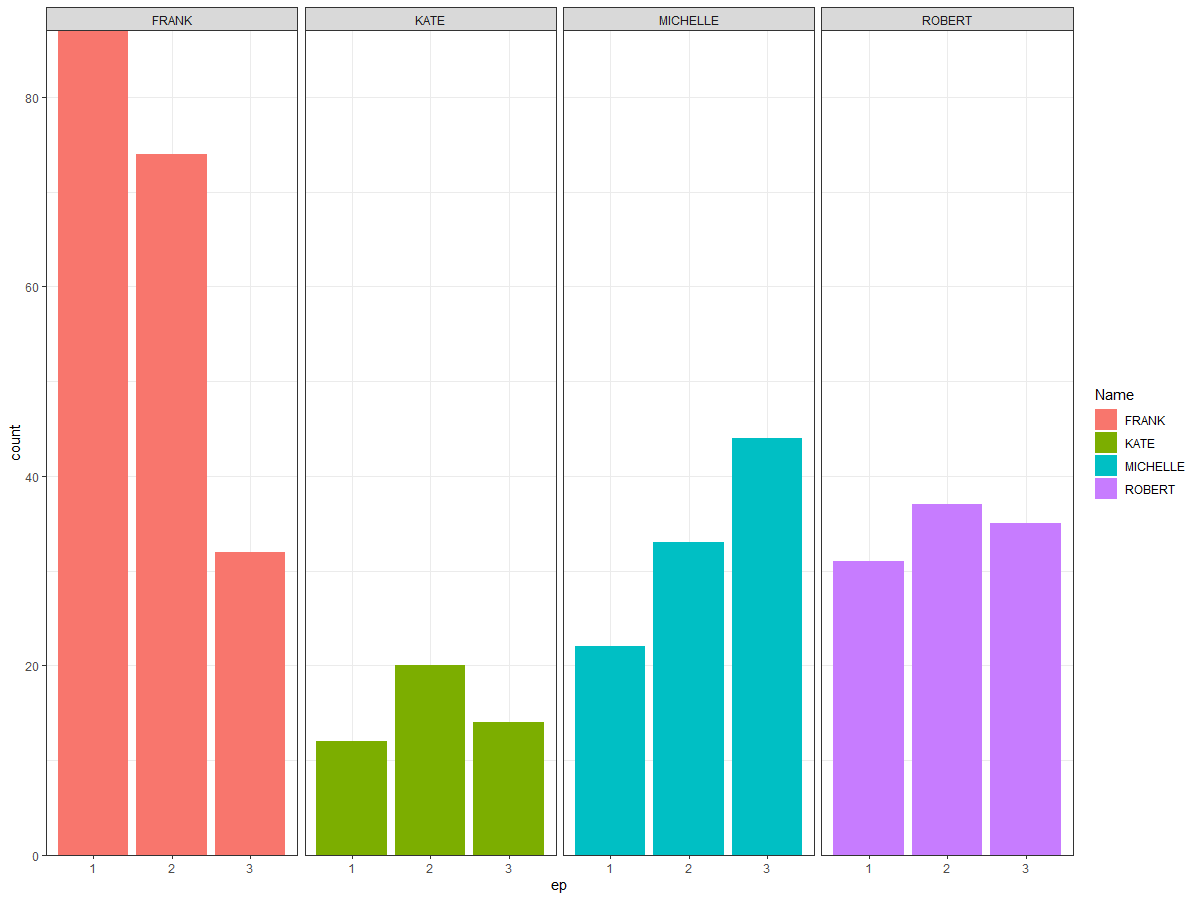
Solution 1: Faceting
As @rdelrossi suggested, one solution is to facet by Name:
library(ggplot2)
ggplot(df, aes(ep,value))
geom_line(aes(colour = Name, group=Name), show.legend = FALSE)
scale_x_continuous(expand = c(0,0))
facet_wrap(vars(Name), ncol = 1, scales = "free_x")
theme_bw()
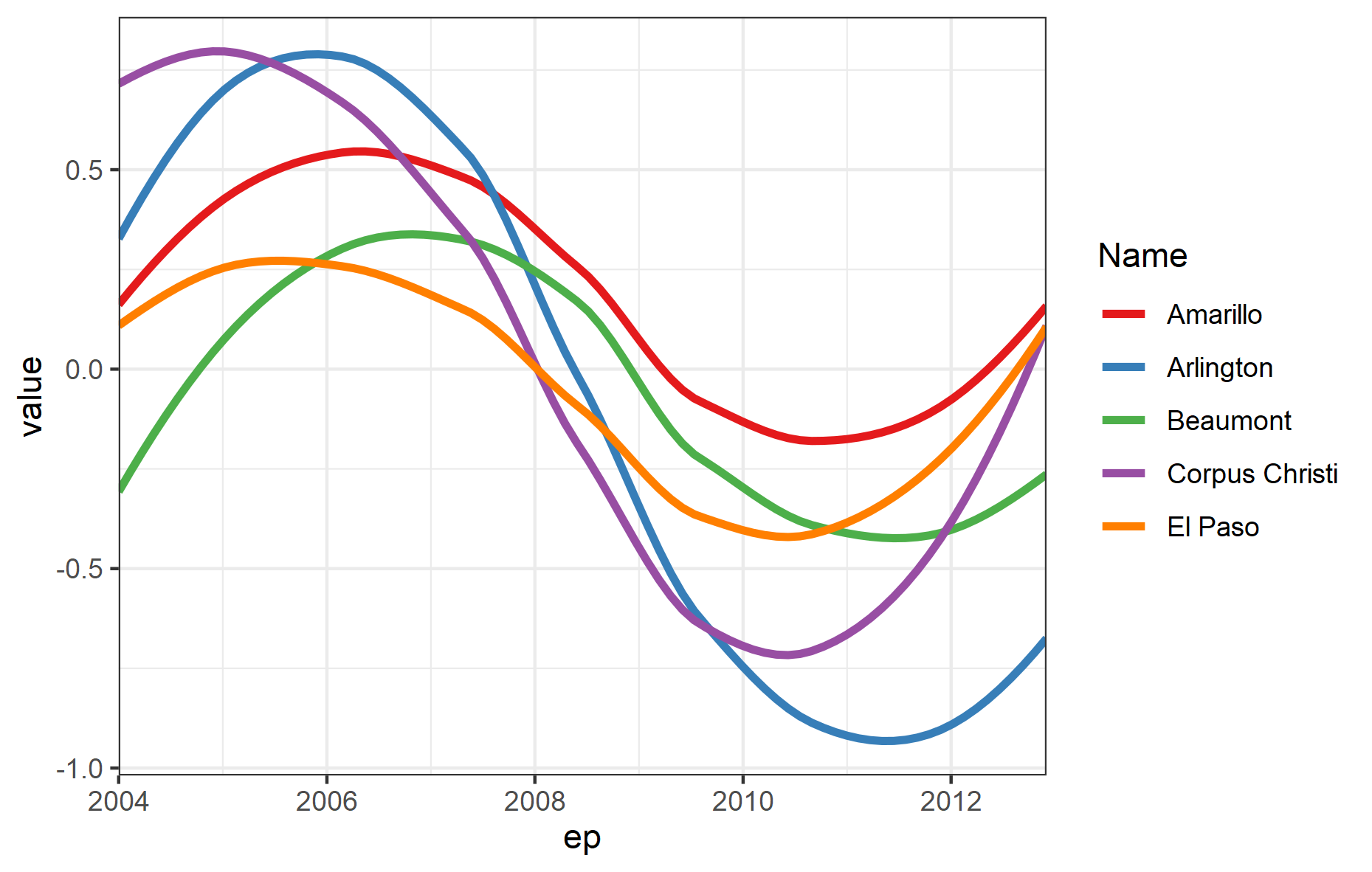
Solution 2: Smoothing
Another option is to use geom_smooth() to smooth out local fluctuations to see larger longer-term trends:
ggplot(df, aes(ep,value))
geom_smooth(
aes(colour = Name, group=Name),
se = FALSE,
span = 1, # higher number = smoother
size = 1.25
)
scale_x_date(expand = c(0,0))
theme_bw()
Solution 3: Lasagna
Sometimes called a "lasagna plot," this is a heatmap with cases on the y axis, time (or whatever) on the x axis, and values mapped to color. It's a different way of comparing changes within (left to right) and between (up and down) individuals.
ggplot(df, aes(ep, Name, colour = value, fill = value))
geom_tile(size = .5)
scale_fill_viridis_c(option = "B", aesthetics = c("colour", "fill"))
coord_cartesian(expand = FALSE)
theme(
axis.text.y = element_text(size = 12, face = "bold"),
axis.title.y = element_blank()
)
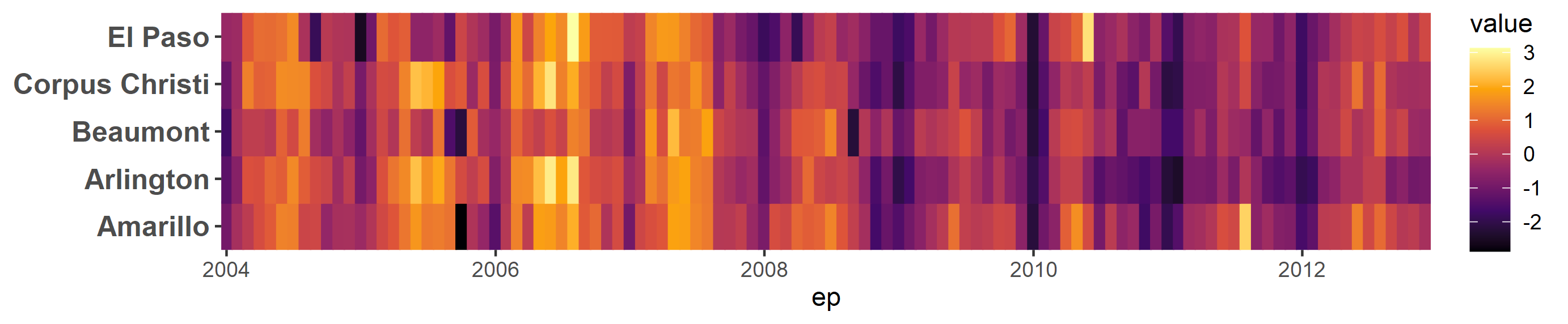
Data prep:
library(dplyr)
library(lubridate)
df <- txhousing %>%
filter(
city %in% c("Beaumont", "Amarillo", "Arlington", "Corpus Christi", "El Paso"),
between(year, 2004, 2012)
) %>%
group_by(city) %>%
mutate(
Name = city,
value = scale(sales),
ep = ym(str_c(year, month))
) %>%
ungroup()
CodePudding user response:
If your readability concern is just the x axis labels, then I think the main issue is that when you use reshape2::melt() the result is that the column ep is a factor which means that the x axis of your plot will show all the levels and get crowded. The solution is to convert it to numeric and then it will adjust the labels in a sensible way.
I replace your use of reshape2::melt() with tidyr::pivot_longer() which has superseded it within the {tidyverse} but your original code would still work.
library(tidyverse)
df <- structure(list(`1` = c(31, 87, 22, 12), `2` = c(37, 74, 33, 20), `3` = c(35, 32, 44, 14)), class = "data.frame", row.names = c("ROBERT", "FRANK", "MICHELLE", "KATE"))
df %>%
rownames_to_column("Name") %>%
pivot_longer(-Name, names_to = "ep") %>%
mutate(ep = as.numeric(ep)) %>%
ggplot(aes(ep, value, color = Name))
geom_line()
Created on 2022-03-07 by the 
Also you can add facet_grid(~Name)
Also you can add
geom_text(aes(label=value), position = position_stack(vjust = .5))