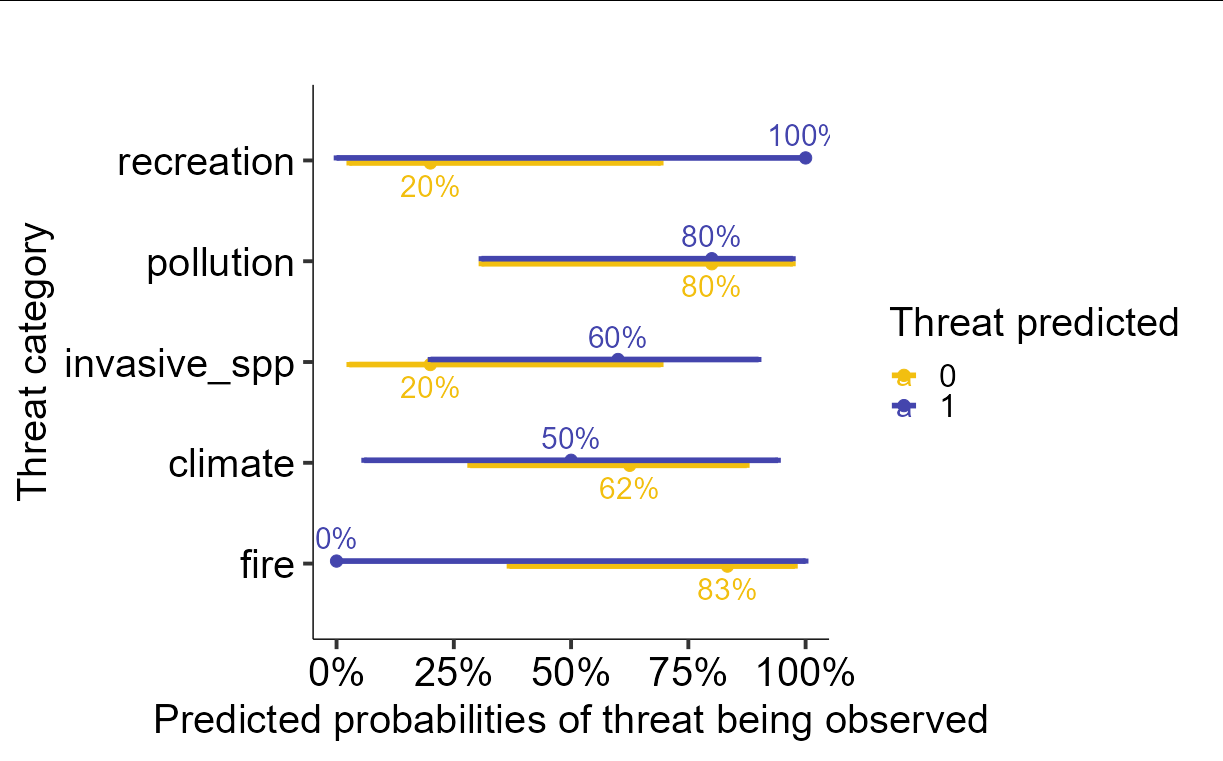
I am trying to make an interaction plot in sjPlot showing percent probabiliites of my outcome under two conditions of my predictive variable. Everything works perfectly, except the show.values = T and sort.est = T arguments, which don't seem to do anything. Is there a way to get this to work? Or, if not, how can I extract the dataframe sjPlot is using to create this figure? Looking for some way to either label or tabulate the displayed probability values. Thank you!
Here is some example data and what I have so far:
set.seed(100)
dat <- data.frame(Species = rep(letters[1:10], each = 5),
threat_cat = rep(c("recreation", "climate", "pollution", "fire", "invasive_spp"), 10),
impact.pres = sample(0:1, size = 50, replace = T),
threat.pres = sample(0:1, size = 50, replace = T))
mod <- glm(impact.pres ~ 0 threat_cat/threat.pres,
data = dat, family = "binomial")
library(sjPlot)
library(ggpubr)
plot_model(mod, type = "int",
title = "",
axis.title = c("Threat category", "Predicted probabilities of threat being observed"),
legend.title = "Threat predicted",
colors = c("#f2bf10",
"#4445ad"),
line.size = 2,
dot.size = 4,
sort.est = T,
show.values = T)
coord_flip()
theme_pubr(legend = "right", base_size = 30)
CodePudding user response:
sjPlot produces a ggplot object, so you can examine the aesthetic mappings and underlying data. After a bit of digging around you will find the default mapping is already correct for the x, y placements of text labels, so all you need to do is add a geom_text to the plot, and only need to specify the labels as an aesthetic mapping. You can get the labels from a column called predicted stored in the ggplot object.
The upshot is that if you add the following layer to your plot:
geom_text(aes(label = scales::percent(predicted)),
position = position_dodge(width = 1), size = 8)
You get
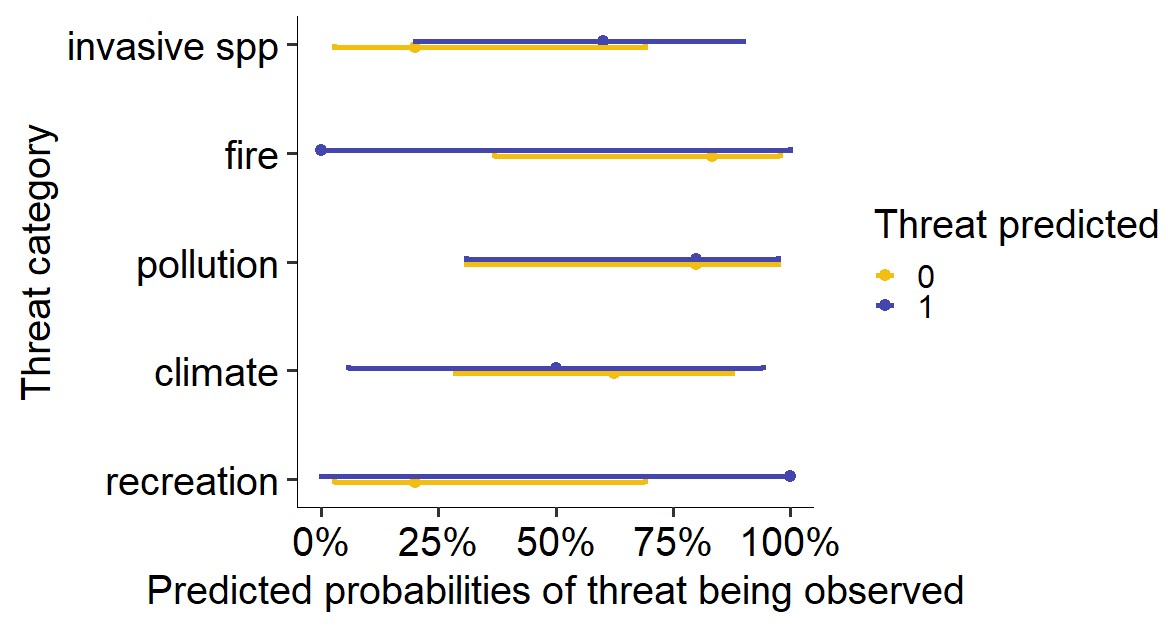
Getting the labels in order is trickier. You have to fiddle with the internal components of the plot to do this. Suppose we store the above plot as p, then we can sort by the predicted percentages by doing:
p$data <- as.data.frame(p$data)
ord <- p$data$x[p$data$group == 1][order(p$data$predicted[p$data$group == 1])]
p$data$x <- match(p$data$x, ord)
p$scales$scales[[1]]$labels <- p$scales$scales[[1]]$labels[ord]
p