Having a DataFrame like below
df = pd.DataFrame({'COUNTRY':['PL', 'FR','NO','SE', 'IT', 'PL'], 'REGION':[1,3,1,2,2,3], SUBREGION':[1,2,3,4,6,8]})
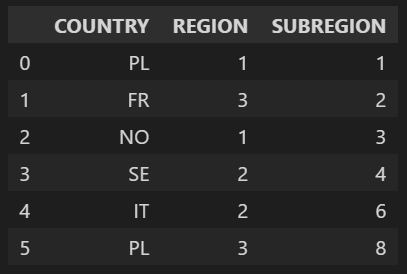
and two lists:
country_list = ['IT', 'PL', 'FR']
region_list = [1,1,3]
I would like to filter the DataFrame on both lists where each item of each list is a pair like a {'PL':1} ensuring that only that combination is selected. That is why a regular filter like:
df[(df['COUNTRY'].isin(country_list)) & (df['REGION'].isin(region_list))]
will present a result that is unsatisfactory:
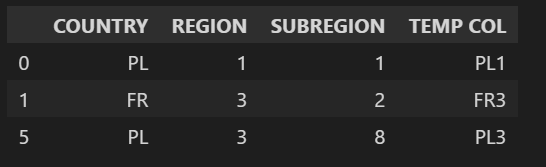
How I go about it for the moment is a very Excel like solution where I create a temp column and merge two lists together to have one key for filtering as below:
df = df.astype({'REGION':'str'})
region_list = list(map(str,region_list))
merged_list = list(zip(country_list,region_list))
merged_list =[''.join(i) for i in merged_list]
df['TEMP COL'] = df['COUNTRY'] df['REGION']
df[df['TEMP COL'].isin(merged_list)]
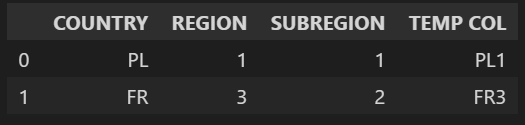
This works but I wanted to check with the community if there is a more elegant approach you are using? Let me just note that having an option to filter on one dictionary instead of two lists would be even superior.
CodePudding user response:
Create helper DataFrame and for filter use default inner join by default both columns:
df = pd.DataFrame({'COUNTRY': country_list, 'REGION': region_list}).merge(df)
print (df)
COUNTRY REGION SUBREGION
0 PL 1 1
1 FR 3 2
Or use Index.isin by MultiIndex and filter in boolean indexing:
df = df[df.set_index(['COUNTRY','REGION']).index.isin(zip(country_list, region_list))]
print (df)
COUNTRY REGION SUBREGION
0 PL 1 1
1 FR 3 2
CodePudding user response:
Here's one approach (almost the same as yours):
out = df[df[['COUNTRY', 'REGION']].apply(tuple, axis=1).isin(zip(country_list, region_list))]
Output:
COUNTRY REGION SUBREGION
0 PL 1 1
1 FR 3 2
CodePudding user response:
You could try it this way:
idx = pd.Series(index=df.index, data=False)
for cl, rl in zip(country_list,region_list):
idx |= ((df['COUNTRY'] == cl) * (df['REGION'] == rl))
df[idx]
Output:
COUNTRY REGION SUBREGION
0 PL 1 1
1 FR 3 2
In this way you do not need to make a surrogate "Excel" like column.