I have a SQL table with about 50 columns, the first represents unique users and the other columns represent categories which are scored 1-10.
Here is an idea of what I'm working with
| user | a | b | c |
|---|---|---|---|
| abc | 5 | null | null |
| xyz | null | 6 | null |
I am interested in counting the number of non-null values per column.
Currently, my queries are:
SELECT col_name, COUNT(col_name) AS count
FROM table
WHERE col_name IS NOT NULL
Is there a way to count non-null values for each column in one query, without having to manually enter each column name?
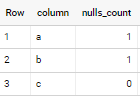
The desired output would be:
| column | count |
|---|---|
| a | 1 |
| b | 1 |
| c | 0 |
CodePudding user response:
I didn't do this in big-query but instead in SQL Server, however big query has the concept of unpivot as well. Basically you're trying to transpose your columns to rows and then do a simple aggregate of the columns to see how many records have data in each column. My example is below and should work in big query without much or any tweaking.
Here is the table I created:
CREATE TABLE example(
user_name char(3),
a integer,
b integer,
c integer
);
INSERT INTO example(user_name, a, b, c)
VALUES('abc', 5, null, null);
INSERT INTO example(user_name, a, b, c)
VALUES('xyz', null, 6, null);
INSERT INTO example(user_name, a, b, c)
VALUES('tst', 3, 6, 1);
And here is the UNPIVOT I did:
select count(*) as amount, col
from
(select user_name, a, b, c from example) e
unpivot
(blah for col in (a, b, c)
) as unpvt
group by col
Here's example of the output (note, I added an extra record in the table to make sure it was working properly):

Again, the syntax may be slightly different in BigQuery but I think thould get you most of the way there.
Here's a link to my db-fiddle -