I am trying to subset a dataframe by multiple values in one column.
The input is the following:
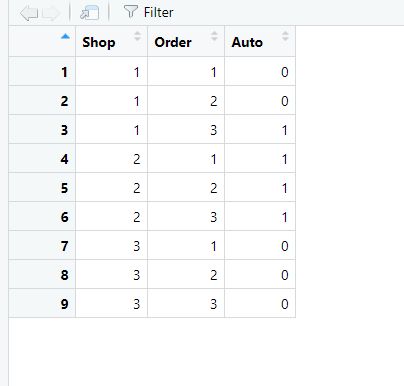
Output should be:
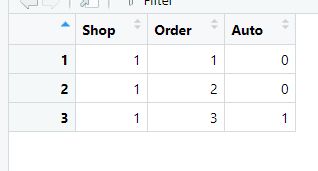
So i want only the rows in the new dataframe, which contains 0 AND 1 in the column "Auto" - grouped for each shop.
Already tried this, but doesnt work:
test <- subset(rawdata, Auto == 0 &Auto == 1)
test <- subset(rawdata, min(Auto) == 0 & max(Auto) == 1)
test<- rawdata[ which(rawdata$Auto'==0 & rawdata$Auto== 1), ]
Thanks for any help. Regards
CodePudding user response:
Please do not add data as images, provide data in a reproducible format
You can select the Shop where both 0 and 1 are present.
library(dplyr)
df %>%
group_by(Shop) %>%
filter(all(c(0, 1) %in% Auto)) %>%
ungroup
# Shop Order Auto
# <dbl> <dbl> <dbl>
#1 1 1 0
#2 1 2 0
#3 1 3 1
data
df <- structure(list(Shop = c(1, 1, 1, 2, 2, 2, 3, 3, 3), Order = c(1,
2, 3, 1, 2, 3, 1, 2, 3), Auto = c(0, 0, 1, 1, 1, 1, 0, 0, 0)),
class = "data.frame", row.names = c(NA, -9L))
CodePudding user response:
It is not very clear what you are trying to do based of your question. If I interpreted it correctly, you want to keep every row of shops where 1s and 0s occur.
To do this one possible solution might be to count the number of rows that each shop has and check wether that value is the same as the sum of auto (means all 1s) or equal to 0 (means all 0s).
If that criteria is met you want all rows of the shop to be excluded.
Look into the function summarise.
CodePudding user response:
Is this what you're looking for?
library(magrittr)
library(dplyr)
#Toy data.
df <- data.frame(Shop = c(1, 1, 1, 2, 2, 2, 3, 3, 3),
Order = c(1, 2, 3, 1, 2, 3, 1 , 2, 3),
Auto = c(0, 0, 1, 1, 1, 1, 0, 0, 0))
#Solution.
df %>%
group_by(Shop) %>%
filter(n_distinct(Auto) > 1) %>%
ungroup()
# # A tibble: 3 × 3
# Shop Order Auto
# <dbl> <dbl> <dbl>
# 1 1 1 0
# 2 1 2 0
# 3 1 3 1
The key idea here is using dplyr::n_distinct() to count the number of unique values in Auto within each Shop group, and subsequently retaining only those groups that have more than 1 n_distinct values.