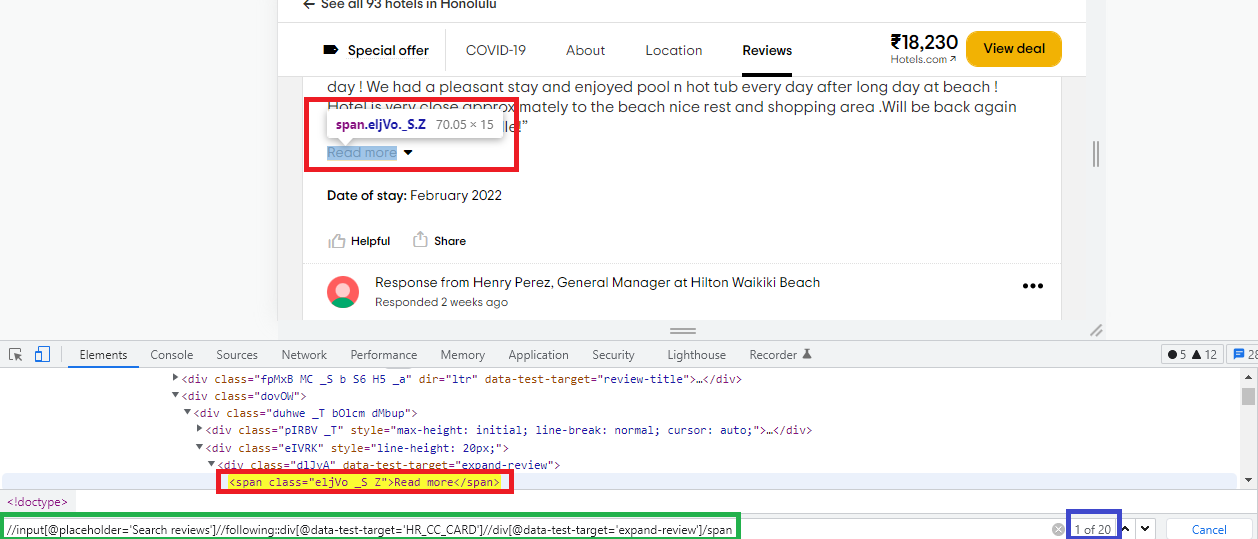
I am getting frustrated trying to find the xpath for the first "Read more" button in the review section of this website: https://www.tripadvisor.com/Hotel_Review-g60982-d209422-Reviews-Hilton_Waikiki_Beach-Honolulu_Oahu_Hawaii.html
I'm trying to scrape the reviews on my macbook, but keep getting an invalid syntax error. I was told that it's because the xpath isn't formatted correctly. All suggestions did not work.
I'm using selector gadget in Chrome, and this time I tried selecting an element with a div. This is what came out
//*[contains(concat( " ", @class, " " ), concat( " ", "eIVRK", " " ))]
Of course it did not work. Then I tried Chromes inspect element, and this is what it came up with
<div style="line-height: 20px;"><div data-test-target="expand-review"><span >Read more</span><span ></span></div></div>
I have no clue what to do with this.
This also generated errors:
driver.find_elements(by=By.XPATH,'//*[@id="component_18"]/div/div[3]/div[3]/div[3]/div[3]/div[1]/div[2]/div').click()
File "/var/folders/6c/jpl964752rv_72zjclrp_8ym0000gn/T/ipykernel_24978/3907164188.py", line 8
driver.find_elements(by=By.XPATH,'//*[@id="component_18"]/div/div[3]/div[3]/div[3]/div[3]/div[1]/div[2]/div').click()
^
SyntaxError: positional argument follows keyword argument
CodePudding user response:
I tested him and it worked
planA
driver.find_element_by_xpath('/html/body/div[2]/div[2]/div[2]/div[4]/div/div[1]/div[2]/div/div/div/div/div[2]/div[1]/div/div[1]/div[2]/div[2]/div/span').click()
planB
driver.find_element_by_xpath('//*[@id="COVID19"]/div/div[2]/div[1]/div/div[1]/div[2]/div[2]/div/span').click()
it is full code
from selenium import webdriver
from time import sleep
def test(key= 1):
options = webdriver.ChromeOptions()
options.binary_location = 'C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe'
driver = webdriver.Chrome('D:\\python\\chromedriver.exe', options=options)
driver.get('https://www.tripadvisor.com/Hotel_Review-g60982-d209422-Reviews-Hilton_Waikiki_Beach-Honolulu_Oahu_Hawaii.html')
sleep(5)
if key == 1:
driver.find_element_by_xpath('/html/body/div[2]/div[2]/div[2]/div[4]/div/div[1]/div[2]/div/div/div/div/div[2]/div[1]/div/div[1]/div[2]/div[2]/div/span').click()
sleep(10)
driver.close()
else:
driver.find_element_by_xpath('//*[@id="COVID19"]/div/div[2]/div[1]/div/div[1]/div[2]/div[2]/div/span').click()
sleep(10)
driver.close()
test(1)
test(2)
CodePudding user response:
You can locate all the Read more link of the reviews within tripadvisor website using the following locator strategy:
Using XPATH:
//input[@placeholder='Search reviews']//following::div[@data-test-target='HR_CC_CARD']//div[@data-test-target='expand-review']/spanSnapshot: