I have a pandas dataframe like as shown below
import pandas as pd
data ={'Count':[1,1,2,3,4,2,1,1,2,1,3,1,3,6,1,1,9,3,3,6,1,5,2,2,0,2,2,4,0,1,3,2,5,0,3,3,1,2,2,1,6,2,3,4,1,1,3,3,4,3,1,1,4,2,3,0,2,2,3,1,3,6,1,8,4,5,4,2,1,4,1,1,1,2,3,4,1,1,1,3,2,0,6,2,3,2,9,10,2,1,2,3,1,2,2,3,2,1,8,4,0,3,3,5,12,1,5,13,6,13,7,3,5,2,3,3,1,1,5,15,7,9,1,1,1,2,2,2,4,3,3,2,4,1,2,9,3,1,3,0,0,4,0,1,0,1,0]}
df = pd.DataFrame(data)
I would like to do the below
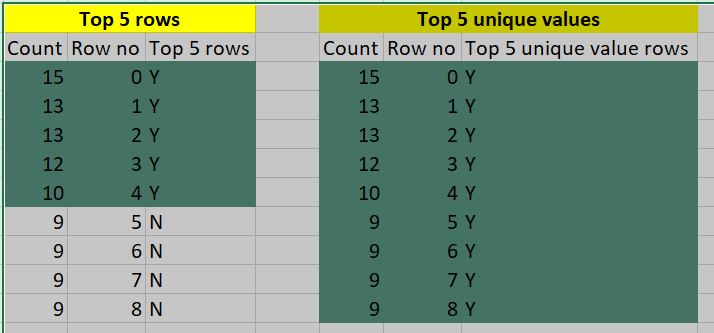
a) Top 5 rows (this will return only 5 rows)
b) Rows with Top 5 unique values (this can return N > 5 rows if the top 5 values are repeating). See my example screenshot below where we have 8 rows for selecting top 5 unique values
While am able to get Top 5 rows by using the below
df.nlargest(5,['Count'])
However, when I try the below for b), I don't get the expected output
df.nlargest(5,['Count'],keep='all')
I expect my output to be like as below
CodePudding user response:
Are you after top 5 unique values or largest top five values?
df =(df.assign(top5rows=np.where(df.index.isin(df.head(5).index),'Y','N'),
top5unique=np.where(df.index.isin(df.drop_duplicates(keep='first').head(5).index), 'Y','N')))
or did you need
df =(df.assign(top5rows=np.where(df.index.isin(df.head(5).index),'Y','N'),
top5unique=np.where(df['Count'].isin(list(df['Count'].unique()[:5])),'Y','N')))
Count top5rows top5unique
0 1 Y Y
1 1 Y Y
2 2 Y Y
3 3 Y Y
4 4 Y Y
5 2 N Y
6 1 N Y
7 1 N Y
8 2 N Y
9 1 N Y
10 3 N Y
11 1 N Y
12 3 N Y
13 6 N Y
14 1 N Y