I've been doing this manually in Excel, but want a way to scale it and figure R or Python is my best bet. That said, I have no idea where to start. Here's an example of the table in Excel:
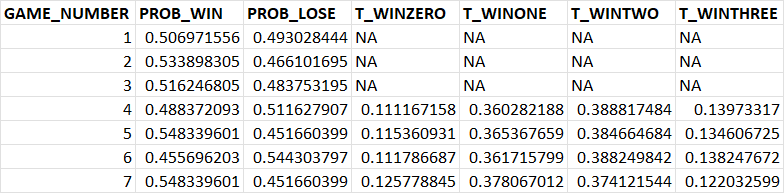
PROB_WIN and PROB_LOSE are the respective probabilities of a team winning or losing said game. Column T_WINZERO is the probability the team won none of their previous three games, T_WINONE is the probability they won one of their previous three games, etc. For instance, the fifth row in T_WINZERO is simply .493 * .466 * .484 (equals .111). One can imagine how this would be difficult to scale once their becomes nearly countless ways to win, for example, 7 out of a team's last 15 games (6,435 ways to be exact).
What I'd like to do is be able to create columns automatically for a team's last N games with these new probabilities (e.g., 0 of last 3, 1 of last 3, 2 of last 3, 3 of last 3 like shown above but for any number of games) using columns PROB_WIN and PROB_LOSE to do so.
In Excel, I'm summing all the probabilities of all the ways winning X of last N games can happen and then dragging the formula down so I'm looking for a similar output in R or Python.
Thanks in advance for the help!
CodePudding user response:
Here is one way.
Rather than transcribing your picture, I created a similar but reproducible set of win probabilities (note that we don't need a column of lose probabilities since these are just the complement of win probabilities)
set.seed(2)
df <- data.frame(GAME = 1:10, PROB_WIN = runif(10, 0.45, 0.55))
df
#> GAME PROB_WIN
#> 1 1 0.4684882
#> 2 2 0.5202374
#> 3 3 0.5073326
#> 4 4 0.4668052
#> 5 5 0.5443839
#> 6 6 0.5443475
#> 7 7 0.4629159
#> 8 8 0.5333449
#> 9 9 0.4968019
#> 10 10 0.5049984
We can write a function that takes a vector of win probabilities and returns the probability of having n wins, taking all possible game sequences into account, like this:
won_n_games <- function(probs, n_wins) {
wins <- asplit(combn(length(probs), n_wins), 2)
losses <- lapply(wins, function(x) setdiff(seq_along(probs), x))
sum(unlist(Map(function(wins, losses) {
prod(probs[wins]) * prod(1 - probs[losses])
},
wins = wins, losses = losses)))
}
We can use this in another function which will create a column of probabilities for winning a given number of the last n games like this:
make_column <- function(probs, n, wins) {
result <- rep(NA_real_, length(probs))
for(i in (n 1):length(probs)) {
result[i] <- won_n_games(probs[(i - n):(i - 1)], wins)
}
result
}
So to create the columns in your data frame we can do:
df$WIN_0_3 <- make_column(df$PROB_WIN, n = 3, wins = 0)
df$WIN_1_3 <- make_column(df$PROB_WIN, n = 3, wins = 1)
df$WIN_2_3 <- make_column(df$PROB_WIN, n = 3, wins = 2)
df$WIN_3_3 <- make_column(df$PROB_WIN, n = 3, wins = 3)
Resulting in
df
#> GAME PROB_WIN WIN_0_3 WIN_1_3 WIN_2_3 WIN_3_3
#> 1 1 0.4684882 NA NA NA NA
#> 2 2 0.5202374 NA NA NA NA
#> 3 3 0.5073326 NA NA NA NA
#> 4 4 0.4668052 0.1256299 0.3763316 0.3743888 0.1236497
#> 5 5 0.5443839 0.1260277 0.3767748 0.3739920 0.1232055
#> 6 6 0.5443475 0.1196847 0.3710328 0.3803585 0.1289240
#> 7 7 0.4629159 0.1106926 0.3614084 0.3895687 0.1383303
#> 8 8 0.5333449 0.1115001 0.3625303 0.3887919 0.1371777
#> 9 9 0.4968019 0.1142016 0.3653846 0.3860178 0.1343960
#> 10 10 0.5049984 0.1261181 0.3773585 0.3738661 0.1226573
Created on 2022-03-19 by the reprex package (v2.0.1)